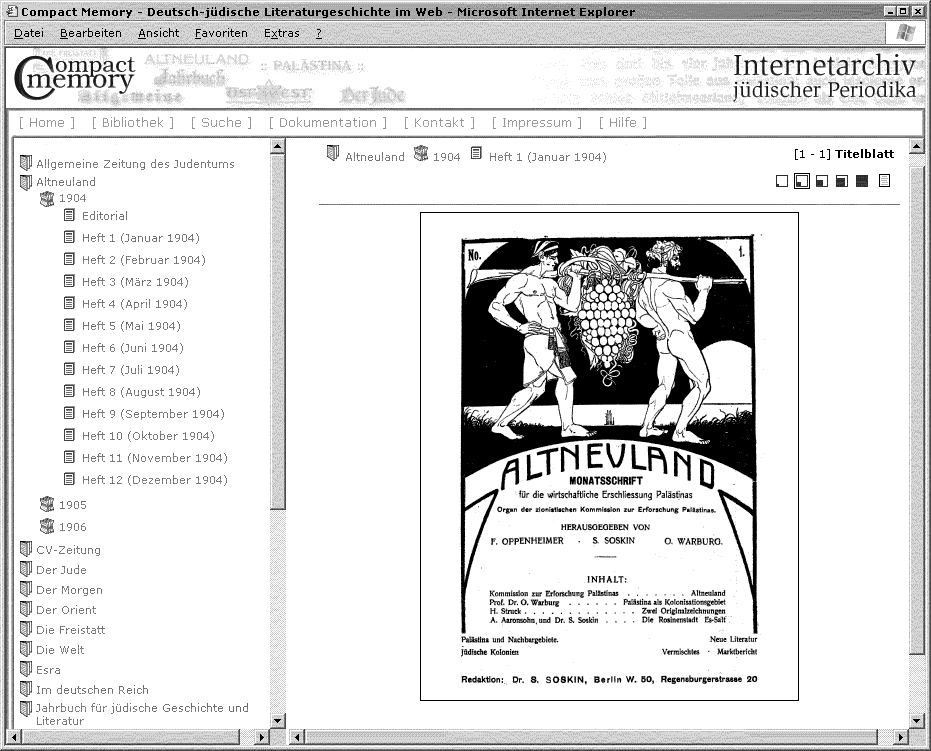
Abb. 1: Auswahl und Anzeige eines Zeitschriftenheftes
»INSELN IM MEER DES BELIEBIGEN«. ARCHITEKTUR UND IMPLEMENTIERUNG EINES INTERNETPORTALS DEUTSCH-JÜDISCHE PERIODIKA
Hans Otto Horch zum 60. Geburtstag
Abstract
Historical newspapers and journals are invaluable sources for the study of the past. Especially, Jewish periodicals provide a detailed impression of the cultural development of Jewry and shed a quite different light on German history. Yet, it is tremendously difficult to obtain and to investigate these sources: Besides ›normal‹ losses (paper destruction et cetera), a great stock of Jewish newspapers was destroyed under the Nazi regime or are scattered all over the world – a fact, that forces a researcher to expensive stays in different libraries or archives and compels librarians to an extra burden of work. Within the funding program Scientific Library Services and Information Systems of the Deutsche Forschungsgemeinschaft the Aachen Chair of German-Jewish Literary History, the Cologne library Germania Judaica and the Town and University Library Frankfurt/Main carry out a digitization project, which already provides more than twenty representative periodicals, containing about 300.000 images in the WWW.
The essay emphasizes the implications and the broad range of problems as well as their solutions in the process of digitizing periodicals. A discussion of the project's technological goals demonstrates the single strategies und procedures to publish large amounts of images, text and bibliographical data in an economic and structured way.
Das Informationszeitalter begrüßt den Philologen, so will es scheinen, jeden Tag mit einer überraschung – zumindest, was die Unterstützung seiner Arbeit durch Informations- und Kommunikationstechnologien betrifft. Die Pionierleistungen der Computerphilologie – an deutschen Universitäten etwa erste, seit den späten 1960er Jahren mit Großrechnern und Lochkarten erstellte Textanalysen, Indices und Editionen – lieferten die Ausgangsbasis einer technologischen Entwicklung, deren Dimension erst allmählich deutlich wird. Personal Computer, preiswerte Speicher- und Distributionsmedien, zunehmend nutzeradäquate Software, schließlich die ubiquitäre Verfügbarkeit des Internets schufen die Rahmenbedingungen eines heute kaum mehr überschaubaren Arsenals an technologischen Verfahren und Applikationen zur Informationserfassung und -distribution.
Dabei erlebt der Philologe den Anbruch dieser neuen ära am denkbar bequemsten Ort – an seinem individuellen Computerarbeitsplatz: In zunehmendem Maß konkurrieren virtuelle Kataloge mit Bibliotheken vor Ort. Dokumentenlieferdienste versenden beliebige Texte per Mail. Exzerpte und Bibliographien verwaltet das persönliche Dokumentenmanagementsystem, und dank automatischer Texterkennungssoftware können auch umfangreichste Corpora nach Schlüsselbegriffen durchsucht werden. Last not least bietet das World Wide Web eine exponentiell wachsende Informationsbasis, die den Gang in ›reale‹ Bibliotheken irgendwann vollends zu erübrigen scheint.
Kaum ein Bereich veranschaulicht die Technisierung und Globalisierung der Philologie so schlagend wie die weltweiten Initiativen zum Aufbau virtueller Bibliotheken. Die Perspektive ist in der Tat atemberaubend: Allein von der Deutschen Forschungsgemeinschaft wurden in den letzten Jahren circa 90 philologisch-bibliothekarische Digitalisierungsprojekte ins Leben gerufen, mit deren Hilfe langfristig die wissenschaftliche Literaturversorgung verbessert und zugleich der stetig ansteigende, aber immer schwerer zu finanzierende Arbeitsaufwand der Bibliotheken verringert werden kann. Ein Schwerpunkt der geförderten Vorhaben liegt dabei auf der ›retrospektiven‹ Digitalisierung, die vorrangig ältere, urheberrechtsfreie Bibliotheksbestände aufbereitet und im Internet zur Verfügung stellt.[1] Das Spektrum ist denkbar breit und reicht von Turfanhandschriften und tibetanischen Archivbeständen über Braille-Musik-Matrizen, Tonaufnahmen semitischer Sprachen und neulateinische Dichtungen bis zum Grimm'schen Wörterbuch. Ein Dutzend Vorhaben widmet sich Zeitschriften und Jahrbüchern beziehungsweise periodisch erschienenem Schrifttum.[2] Alle Projekte gehen im Konzept der Verteilten Digitalen Forschungsbibliothek auf und leisten heute bereits unschätzbare Dienste, wo es gilt, weltweit verstreute oder entlegene Bestände virtuell zusammenzuführen und den mit ihnen befassten Disziplinen einen ungehinderten Zugriff auf das Material zu bieten.
Vergleicht man die deutsche Digitalisierungslandschaft mit Angeboten aus den USA,[3] ist freilich festzustellen, dass der Aufbau digitaler Fachbibliotheken hierzulande gerade erst das Anfangsstadium hinter sich gelassen hat. Dies betrifft nicht die Auswahl teilweise recht exotischer Textcorpora oder das Faktum, dass der Bestand von fachübergreifend einschlägigen und vielgenutzten Quellen nur langsam wächst. Vielmehr sei, summiert die DFG die Entwicklung der letzten Jahre, die »Verteilte digitale Forschungsbibliothek [...] zunächst unstrukturiert gewachsen« und setzt als ›Gegenmaßnahme‹ derzeit auf die »Einrichtung eines Portals ›Sammlung digitaler Drucke‹, mit dem Ziel, retrodigitalisierte Dokumente leichter auffindbar zu machen«:[4]
Erkennbare Defizite bestehen [...] gegenwärtig noch bei der Einbindung digitaler Angebote in vorhandene Informationssysteme, insbesondere einer über die jeweilige Besitzbibliothek hinausgehenden Erschließung der digitalisierten Bestände und einer aktiven Bekanntmachung der verfügbaren Materialien.[5]
Der »Eindruck einer Vielfalt unterschiedlicher Ressourcen« gipfelt in der »Unübersichtlichkeit des vorhandenen Angebots«, das »auf der Ebene der überlokalen Informationssysteme dann völlig undurchdringbar« wird, »wenn [...] eine unsystematische und weitgehend vom Zufall abhängige Auswahl der jeweils nachgewiesenen Digitalisierungsaktivitäten hinzutritt«.[6] Unter praktischem Gesichtspunkt hat es darüber hinaus oft noch den Anschein, dass viele Projekte technologisch bedingte Inkonsistenzen aufweisen beziehungsweise in summa keiner homogenen Architektur folgen. Ebenso scheint bislang nur wenig Einigkeit über allgemeine Produktionskriterien und -verfahren zu bestehen, die eine ökonomische, ressourcensparende Verarbeitung umfangreicher Corpora gewährleisten.[7] Die unter funktionalen und ergonomischen Aspekten sehr unterschiedlich gestalteten Websites deutscher Digitalisierungsprojekte lassen den Nutzer erahnen, welche Schwierigkeiten die Ermittlung und Umsetzung produktions- und designtechnischer Standards derzeit noch bereiten.[8]
Ungeachtet dieser Problematik, auf die im Folgenden näher eingegangen werden soll, hat sich das Konzept der internetgestützten Informationsversorgung als integraler Bestandteil und richtungsweisender Imperativ deutscher Bibliotheks- und Bildungspolitik etabliert – allen kulturpessimistischen Unkenrufen zum Trotz, eine »zur Cyberscience hochgerüstete Wissenschaft« würde letztlich »nichts weniger als ihre Wissenschaftlichkeit ein[büßen]«.[9] Gehörte es vor knapp zehn Jahren fast noch zum guten Ton, die ›Technisierung‹ der Geisteswissenschaft rundheraus abzulehnen, ist der »Außenseiterstatus« der die Zeichen der Zeit verkennenden »Verächter und Verweigerer« längst evident geworden.[10] Kein Wissenschaftler, der die Effizienz von Personal Computer und World Wide Web erkannt hat, will fortan auf diese Arbeitshilfen verzichten. Nur die letzten standhaften Verteidiger einer überkommenen Buchdruckromantik leugnen heute noch das Faktum, dass auch Gutenbergs revolutionärer Quantensprung in erster Linie eine technologische Leistung darstellte, deren Ergebnis – zunächst als Teufelswerk verschrien – innerhalb kurzer Zeit fest in den frühneuzeitlichen Wissenschaftsalltag integriert wurde, diesen gar allererst konstituiert hat.[11]
Die Grundsatzdebatte kann angesichts jüngerer bildungs- und forschungspolitischer Entscheidungen, die sich frühen DFG-Empfehlungen anschließen und auf den nachhaltigen Ausbau der digitalen Informationsversorgung drängen, als beendet gelten.[12] In Anbetracht der voll im Gange befindlichen »Umgestaltung der wissenschaftlichen Informationslandschaft«,[13] die – wie Eli M. Noam 1995 prophezeite – die klassischen Strukturen der universitären Wissensvermittlung tief greifend wandeln wird,[14] gewinnt die oft als ›Technophobie‹ getadelte Skepsis der Geisteswissenschaftler allerdings neuerlichen Auftrieb. Der Ursprung dieser pessimistisch-misstrauischen Haltung ist genauer zu lokalisieren: Als ›Angst vor dem Unbekannten‹ oder »mangelnde Informationskompetenz bei den Nutzern«[15] ist diese aus Unsicherheit und Unkenntnis resultierende Befangenheit gegenüber neuen Technologien ein nicht zu unterschätzender Faktor, der schon im Vorfeld über Wohl und Wehe jeder Digitalisierungsinitiative entscheidet.[16]
Doch wer ist der ›Nutzer‹? Im Zeitalter des ›analogen‹ Informationsaustausches, in der ära der klassischen Bibliothek, lag die Antwort auf der Hand: der ›Leser‹, im universitären Bereich also vor allem Wissenschaftler und Studierende. In der Epoche der hybriden Bibliotheken und Archive,[17] die neben Schrifttum in Buch- oder Microform alle erdenkbaren Arten und Formate von digitalisierten Materialien bereitstellen müssen, wird der Bibliothekar beziehungsweise Archivar zunächst selbst zum Nutzer – an erster Stelle zum ›User‹ technischer Apparaturen, Computeranwendungen sowie Format- und Auszeichnungssprachen zur Erfassung, Indizierung und Verbreitung von Informationen. Zwar soll nicht unterstellt werden, dass das Bibliotheks- und Archivpersonal bislang einen Bogen um den Computer gemacht hätte. Die Anforderungen, die heute an den Bibliothekar und Archivar gestellt werden, unterscheiden sich jedoch immens von Fertigkeiten, wie sie seit den 1970er Jahren hinsichtlich der EDV-gestützten Katalogisierung und Datendistribution verlangt wurden. Nicht allein der neue Medientypus, vor allem die technische Peripherie zwingt zur grundlegenden Neuorientierung:
Nicht nur die Andersartigkeit der Medien, auch die gleichzeitig veränderte Welt der Informationstechnik, die schnellen Netze, die hohe Speicherdichte und die Diversifikation der Informationsmärkte stellen unsere Vorstellungen radikal in Frage.[18]
Amerikanische Digitalisierungsspezialisten insistieren daher zurecht darauf, dass jeder Initiative die selbstkritische Bewertung der eigenen technischen Kompetenz vorausgehen muss:
The impulse to embrace things digital is strong, but too often infrastructure – costs, personnel, systems, and preservation – gets insufficient thought and delivery falls short of the promise. Information professionals can little afford to make mistakes in initiating and maintaining digital programs. They must assess carefully the pros an cons of technology choices in a cultural context. The best way to ensure good decisions is to became a knowledgeable consumer of the technology.[19]
Der ›vernetzte‹ Bibliothekar muss über Erfahrungen im Projektmanagement verfügen, vor allem aber technisches Wissen und Urteilsvermögen mitbringen. Der Erwerb dieser Fertigkeiten bleibt allerdings mangels längerfristiger, flächendeckender Erfahrungen im Digitalisierungsbereich heute noch meist seiner Eigeninitiative überlassen. Entsprechende Ausbildungsmaßnahmen, die normative, technische Infrastrukturen und Standards voraussetzten, stellen bislang ebenso eine Ausnahme dar wie allgemein gültige übereinkünfte, die die praktische Durchführung von Digitalisierungsprojekten zu regeln hätten. Technisch-inhaltliche Empfehlungen, vereinzelte Projektdokumentationen oder Sammelwerke sowie neue Diskussionsforen zeigen,[20] dass auf zahlreiche drängende Fragen noch keine verbindlichen Antworten gefunden wurden. Abhilfe könnte eine repräsentative, didaktisch eingängige Bündelung des erreichten Kenntnisstandes nach Vorbild amerikanischer Standardwerke schaffen,[21] die den betroffenen Bibliothekaren, Archivaren und Wissenschaftlern als richtungsweisender Ratgeber zu dienen hätte.[22] Der Gewinn einer zunehmenden ›Technosensibilisierung‹ liegt auf der Hand:
[...] digital projects are usually experimental and permit a rare and precious let's-try-it-and-see attitude. This early period of technological innovation turns you and your staff into valuable assets for your community. You have an expertise that has been dearly bought by your institution, and its investment in you and the conversion projects you manage means that you have its attention.[23]
Die technologischen und praktischen Widerstände wiegen desto schwerer, als die Forderung nach dem Auf- und Ausbau digitaler Archive und Bibliotheken aus Gründen der zeitgemäßen Informationserhaltung, -verwaltung und -versorgung immer lauter erhoben wird. Zwar ist zu erwarten, dass das »learning-by-doing« viele Defizite allmählich kompensiert, institutionelle Schwierigkeiten überwunden werden und sich im Zuge nationaler und internationaler Kooperationen – so genannte »Collaboratories« – einheitliche Standards etablieren.[24] Gegenwärtig sind die Planer jedes Digitalisierungsprojekts aber bereits im Vorfeld ihrer Anstrengungen mit einer Reihe weitreichender Fragestellungen konfrontiert, die im technischen und distributiven Bereich spezielle Design- und Produktionsstrategien nach sich ziehen.
Die Crux jedes Projekts ist selbstverständlich die Finanzierung eines solchen Vorhabens, wobei die Aussichten seit Start des DFG-Förderprogramms zur ›Retrospektiven Digitalisierung von Bibliotheksbeständen‹ weniger trübe als in anderen Wissenschaftsbereichen sind.[25] Dennoch bleibt festzuhalten: Digitalisierungsprojekte sind sehr kostenintensiv, wobei oft übersehen wird, dass gerade der zur Realisierung der Pläne unverzichtbare technische Unter- und überbau erhebliche finanzielle Investitionen erfordert. Dies betrifft zum einen die Herstellung der so genannten Digitalisate, zum anderen die Finanzierung leistungsstarker Hardware. Weitaus kostenintensiver ist jedoch der Investitionsaufwand im Softwarebereich: Selbst wenn ein geeignetes Dokumentenmanagementsystem gefunden wurde, mit dem alle Arbeitsschritte von der Erfassung bis zur Präsentation der Quellen durchgeführt werden können, verursachen Software-Anpassungen stets weiteren Finanzierungsbedarf. Inwiefern die gewählte Software die anstehenden Aufgaben allerdings tatsächlich zu bewältigen vermag, erfordert wiederum technische Urteilsfähigkeit. Spitzentechnologie – hier sollten keine Zugeständnisse gemacht werden – ist teuer und erfordert professionelle Kenntnisse. Die Verwendung veralteter Systeme oder die Entscheidung, den Auf- oder Ausbau der technischen Infrastruktur ›Hobbyprogrammierern‹ zu überlassen, heißt, im sensibelsten Bereich des Projekts eine Zeitbombe zu plazieren.
Die Auswahl des Corpus, das digitalisiert werden soll, hat sich einerseits technischen Design- und Produktionsmöglichkeiten zu beugen: Da der finanzielle Aufwand erheblich ist, wird jeder Projektträger früh Anschlussvorhaben ins Auge fassen und nur in Verfahren investieren, von denen Folgeprojekte profitieren können. Andererseits müssen verfahrenstechnische Strategiekonzepte die ökonomischen und inhaltlichen Auswahlkriterien berücksichtigen, wobei es grundsätzlich zwischen ›guten‹ und ›schlechten‹ Entscheidungsparametern zu unterscheiden gilt:[26] Ob die Digitalisierung zur Sicherung gefährdeter Bibliotheksbestände beiträgt und langfristig die herkömmliche Microverfilmung ablöst, spielt in diesem Zusammenhang eine nachgeordnete Rolle:
Digitalisierung macht die Aufbewahrung der Originale nicht überflüssig; sie löst auch nicht die konservatorischen Probleme der Bibliotheken. Aber sie erleichtert die Benutzung historischer Texte in entscheidender Weise und ist geeignet, neue Fragestellungen anzuregen.[27]
Entscheidend ist vielmehr, dass Projekte dieser Art unter dem Primat stehen, »durch den Einsatz digitaler Technik die wissenschaftliche Literaturversorgung zu verbessern«; sie gewährleisten den »Direktzugriff auf für die Forschung und Lehre wichtige Bestände« sowie den »Mehrfachzugriff auf vielgenutzte Literatur« und haben »die digitale Bereitstellung schwer zugänglicher Bestände« wie auch »die erweiterte Nutzung bisher nur wenig bekannter Materialien« zu sichern.[28]
Die praktischen Konsequenzen, die diese DFG-Prämissen für die Corpus-Auswahl nach sich ziehen, liegen auf der Hand und fordern spezielle design- und produktionstechnische Vorentscheidungen. Folgende Faktoren sind hier von ausschlaggebender Bedeutung:
→ Quantität – Die Stärke von Hard- und Softwaresystemen besteht darin, große Datenmengen erfassen, verwalten und aufbereiten zu können. Auf Grund des finanziellen und organisatorischen Aufwands sowie der anzustrebenden, möglichst hohen Nutzerfrequenz sollte bei der Auswahl zu digitalisierender Materialien bewusst auf ›Masse‹ gesetzt und Corpora bereitgestellt werden, die wenigstens einige zehn- oder hunderttausend Seiten umfassen. Die technische Infrastruktur muss die problemlose Erfassung und Wiedergabe großer, dabei in der Regel heterogener Datenmengen garantieren, wobei stets das oft eingeschränkte, technische Know-how der Bearbeiter zu berücksichtigen ist.
→ Simultaneität – Es ist keine übertriebene Schätzung, dass mit Beginn der Förderung eines Digitalisierungsprojekts bis zur Präsentation erster Ergebnisse einige Jahre vergehen – ein Umstand, der weder die Projektträger noch die Nutzer befriedigt. Der technische Produktionsweg sollte daher zwei kategoriale Bedingungen erfüllen: Erstens sind die einzelnen Produktionsschritte zu modularisieren, so dass sukzessiv autarke Ergebnisse zur Verfügung gestellt werden können. Zweitens darf zwischen der primären Erfassung der Daten und ihrer Bereitstellung im Internet möglichst kein Zeitverlust entstehen. Konkret bedeutet dies einerseits, dass ein aus diversen Gründen jederzeit möglicher Projektabbruch der Trägerinstitution keinen allzu großen Schaden zufügt. Andererseits ist technisch zu gewährleisten, dass das Ergebnis jeder Aktion der Bearbeiter sofort dem Endnutzer bereitgestellt wird.
→ Ubiquität – Selbstverständlich müssen die digitalisierten Bestände global verfügbar sein, in gleicher Qualität und Quantität wie am Erfassungsort, unabhängig von individuell genutzten Hard- oder Softwareplattformen. Im Netzwerk der verteilten digitalen Bibliothek, die überregionale oder internationale Kooperationen anstrebt, ist ferner technisch zu gewährleisten, dass die Datenerfassung ohne größeren Aufwand von jedem beliebigen Standort aus durchgeführt werden kann. Dies impliziert, dass die Datenbasis migrationsfähig zu sein hat: Sie muss – nicht nur aus Gründen der Langzeitsicherung – in andere standardisierte Formate und Speichermedien überführbar sein; alle ›eigenen‹ Daten müssen, zum Beispiel zum Zweck der Verbundrecherche, verlustfrei in ›fremde‹ Systeme überspielt werden können wie umgekehrt die Integration von Fremddaten ins lokale System gesichert sein muss.
Der Aufbau einer effizienten Produktionslinie, die große, heterogene Datenmengen ohne Zeitverzug zur ubiquitären Nutzung im Internet aufbereitet, bildet den technologischen Fokus des DFG-Kooperationsprojekts »Retrospektive Digitalisierung jüdischer Periodika im deutschsprachigen Raum« (www.compactmemory.de), das seit Frühjahr 2000 vom Aachener Lehr- und Forschungsgebiet Deutsch-jüdische Literaturgeschichte, dem Sondersammelgebiet Judentum der Frankfurter Stadt- und Universitätsbibliothek sowie der Kölner Bibliothek Germania Judaica durchgeführt wird. Im Verlauf von sechs Jahren soll der Großteil der seit Ende des 18. Jahrhunderts im deutschen Sprachraum erschienenen jüdischen Zeitschriften, Zeitungen und Jahrbücher erschlossen und bereitgestellt werden. Das Vorhaben schließt eine gravierende Lücke, die bislang die Arbeit der Jüdischen Studien maßgeblich erschwerte: Einerseits bilden die rund 5.000 jüdischen Periodika, die seit dem 17. Jahrhundert weltweit erschienen, ein gewaltiges, gar nicht zu überschätzendes Quellenreservoir der jüdischen Geschichte und Kultur.[29] über drei Jahrhunderte versuchten jüdische Periodika alle wissenschaftlichen, beruflichen, literarischen, pädagogisch-didaktischen beziehungsweise geistigen Bedürfnisse ihrer Leser zu befriedigen, wodurch sie zu einem kulturhistorisch einmaligen ›Archiv‹ wurden, das sämtliche religiösen, politischen, sozialen und kulturellen Richtungen innerhalb des Judentums dokumentiert.[30] Andererseits sind die erhaltenen Bestände, vor allem infolge der Verluste im Zweiten Weltkrieg und der systematischen Zerstörungen der Nazis, in alle Himmelsrichtungen zerstreut und vollständige Jahrgänge nur an wenigen Bibliotheken erhalten. Wegen ihres schlechten Erhaltungszustandes gelangt das Gros der Originale längst nicht mehr in den Leihverkehr, so dass interessierte Forscher und Laien zu häufigen und kostspieligen Bibliotheksreisen gezwungen sind, was angesichts der hohen Nutzungsfrequenz jüdischer Periodika auch für das Bibliothekspersonal einen erheblichen zusätzlichen Arbeits- und Zeitaufwand bedeutet.
Die erste Forderung bestand folglich darin, die gemäß ihrer historischen Bedeutung, heutigen Nutzungsfrequenz und technischen Tauglichkeit ausgewählten Periodika dem Nutzer per Internet am individuellen Arbeitsplatz zur Verfügung zu stellen. Die Präsentation des insgesamt rund 700.000 Seiten umfassenden Corpus sollte einen zugleich ökonomischen, ergonomisch sinnvollen und intuitiven Zugriff gestatten – Kriterien mithin, die in Anbetracht der enormen Menge zu digitalisierender Analogdaten selbstverständlich auch für die bibliothekarische Erfassung der Daten gelten.[31] Zudem war zu garantieren, dass dem User erste Ergebnisse ohne Zeitverzug in Form eines strukturierten Archivs navigier- beziehungsweise skalierbarer Grafiksammlungen bereitgestellt werden können.
Abb. 1: Auswahl und Anzeige eines Zeitschriftenheftes
Wie in einer ›realen‹ Bibliothek wählt der Besucher zunächst das Periodikum über einen Navigationsbaum aus, um über den gewünschten Jahrgang zur gesuchten Nummer zu gelangen (siehe Abb. 1). Die Anzeige der Images, in denen man wie im papierenen Original ›blättern‹ kann, erfolgt in den gängigen Grafikformaten; separate Optionen dienen der Thumbnailansicht, der Vergrößerung beziehungsweise Verkleinerung sowie dem Druck oder Download der Images.
Die Bereitstellung der Grafiken erfolgt mit dem spezifisch auf den Bedarf von Digitalisierungsprojekten zugeschnittenen Produkt Visual Library der Firma semantics. Diese Softwareplattform ermöglicht mit den Modulen Library Manager und Library Scout die strukturierte Erfassung, Indizierung, Volltexterkennung, Bearbeitung und Bereitstellung beliebiger grafischer und textueller Materialien im Internet.[32] Dabei setzt der Library Manager als zentrales Arbeitswerkzeug das Digitalisierungsteam in den Stand, große Mengen von Grafiken übersichtlich und schnell auf einen lokalen Datenbankserver zu überspielen (circa 1.000 Images pro Stunde). Ein Vorschaufenster zeigt wahlweise den Inhalt des Quellverzeichnisses an, aus dem Images per Drag-and-Drop ins Zielverzeichnis kopiert werden. Im integrierten Grafikbetrachter werden die Images einzeln oder in Form von Thumbnails aufgerufen und in einem Arbeitsgang von Schattierungen oder Verschmutzungen gereinigt. über einen Navigationsbaum, der die serverinterne Zielverzeichnisstruktur abbildet, legt der Bearbeiter neue, annotierbare Zeitschriftentitel, Jahrgänge oder Hefte an, wobei jedes Image zudem typisierbar ist (Titelblatt, Inhaltsverzeichnis, Artikel und so weiter). Mit diesen Arbeitsschritten stehen die erschlossenen Materialien unmittelbar unter Verwendung des Library Scouts in Form dynamisch generierter Webseiten zu Recherchezwecken zur Verfügung.
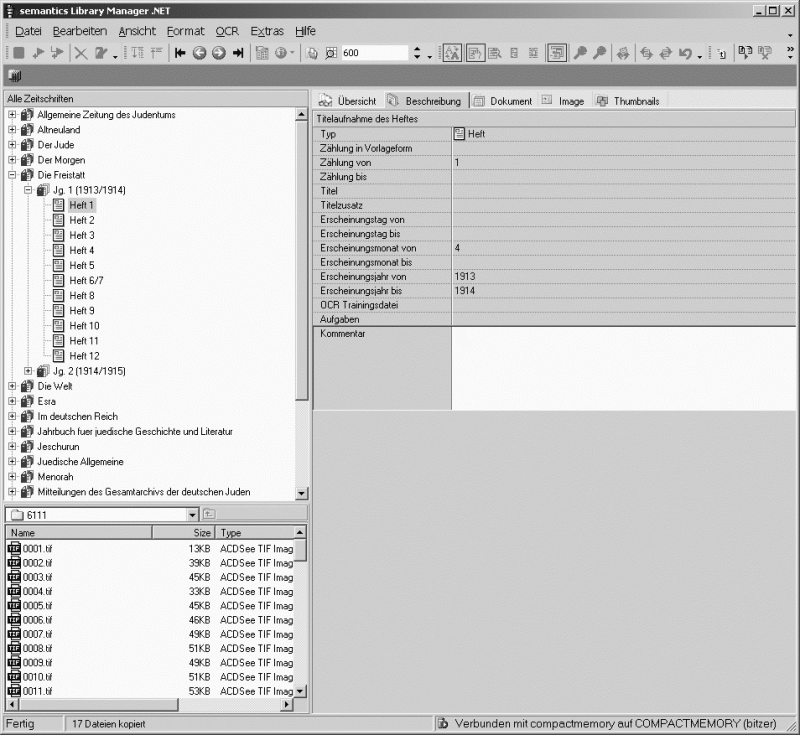
Abb. 2: Library Manager – Einspeisung der Images ins lokale Verzeichnissystem
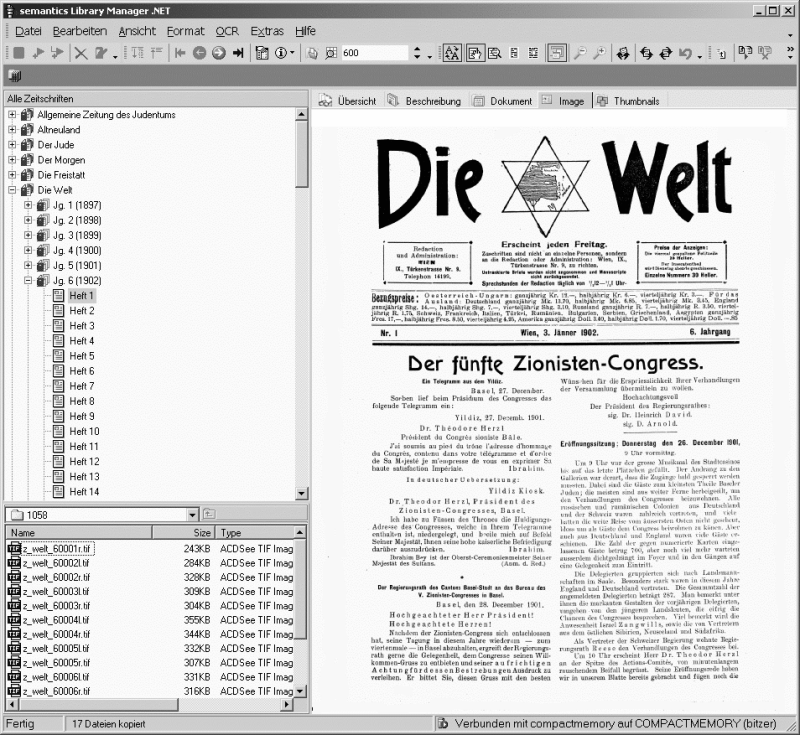
Abb. 3: Library Manager – Imageansicht
Ein Vorteil dieses ersten Produktionsschritts besteht darin, große Mengen digitalen Quellenmaterials ohne Umschweife im Internet zur Verfügung zu stellen. Die Datenerfassung folgt ergonomischen und ökonomischen Prinzipien und setzt keine besonderen technischen Kenntnisse voraus. Darüber hinaus ist diese Phase der Produktion vollkommen autark: Mit geringem Aufwand lassen sich auch weltweit verstreute Materialien in Form virtueller Gesamtbestände zentralisieren, auf die fortan global zugegriffen werden kann. Der Umstand, dass in diesem Stadium keine digitalen Volltexte angeboten werden und das Archiv erst oberflächlich strukturiert ist – im Fall von Periodika gemäß ihrer ›natürlichen‹ Hierarchie (Titel, Jahrgang, Einzelheft) –, erweist sich nur auf den ersten Blick als Nachteil: Waren zuvor aufwändige, oft erfolglose Bibliotheksreisen, Archivaufenthalte oder Bestellvorgänge nötig, wird der Nutzer die bloße Verfügbarkeit bislang schwer zugänglicher Corpora – und sei die Erschließungstiefe vorläufig noch so gering – als ungemeine Arbeitserleichterung begrüßen. Bibliotheken und Archive wiederum werden es zu schätzen wissen, knappe Personalressourcen schonen und die bedrohten Originale schützen zu können.
Diese einfache Bereitstellungsform, die als erster, selbstständiger Produktionsschritt angestrebt werden sollte, mag in manchen Fällen bereits vollkommen genügen – sie stellt jedenfalls ein vergleichsweise einfach, günstig und schnell zu erzielendes Arbeitsergebnis dar, das Nutzer und Anbieter gleichermaßen entlastet. Die geringe Komplexität dieses Verfahrens, das sich leicht auf andere Publikationstypen oder überlieferungsformen applizieren lässt, mag ferner ein Argument für Institutionen darstellen, die bislang keine Erfahrungen im digitalen Bereich gesammelt haben, dieses Segment jedoch aus Gründen der ›Selbsterhaltung‹ rasch besetzen sollen:
Es steht den Geisteswissenschaften nicht mehr frei, sich aus den wandlungsintensiven Bedingungen der Kommunikation herauszuhalten. Und wenn dies [...] im Stillen oder lautstark gefordert wird, dann um den Preis der Selbstmarginalisierung. [...] Was jetzt im Internet als Wissensbestand und Geltungsanspruch nicht angemessen markiert wird, kann mittelfristig bereits von der Weltkarte der geläufigen Kenntnisse verschwunden sein. Es gerät, wenn es für eine computergestützte Benutzung nicht in mediengerechter Form zur Verfügung steht, an den Rand jenes Feldes, das als Raum des allgemein Wissenswerten betrachtet werden kann.[33]
Sofern das Corpus eine tiefere Erschließungsebene erfordert oder die entsprechende Nachfrage besteht, sollten sich Digitalisierungsvorhaben nicht darauf beschränken, Quellen als ›Loseblattsammlungen‹ anzubieten. Eine wichtige Vorgabe, die die Attraktivität eines Digitalisierungsprojekts sichert, besteht bekanntlich darin, dass die Effizienz des Zugriffs auf das Textcorpus die hergebrachten Möglichkeiten des Buchs oder der Mircoform übersteigen sollte. Dies betrifft vor allem die Recherchemöglichkeiten.
Keinesfalls wollen die Nutzer bei jeder neuen Fragestellung immer wieder eine Unzahl von Grafiken nach den gesuchten Materialien durchsuchen – eine mühsame und zeitraubende Prozedur, die schon die Arbeit mit Microfilmen oder papierenen Vorlagen erschwerte. Die Minimalerwartung der Benutzer besteht selbstverständlich darin, die den analogen ›Originalen‹ entsprechenden digitalen ›Kopien‹ einsehen zu können. Darüber hinaus will der User direkt auf zugehörige bibliographische Kerndaten zugreifen sowie in den digitalen Volltexten recherchieren. Als separater Produktionsschritt, der von der Einspeisung der Grafiken ebenso wie von der Erfassung der Volltexte getrennt werden sollte, mag die Erschließung der bibliographischen Daten relativ unaufwändig und unproblematisch sein – allerdings nur, sofern es sich um Monographien handelt: Hinter einem eindrucksvollen Archiv von abertausend Seiten verbergen sich oft nur einige Hundert Titelaufnahmen, die eventuell längst erfasst wurden oder kurzfristig katalogisiert werden können.[34] Die normkonforme Katalogisierung unselbstständig erschienener Literatur erfordert hingegen einen weitaus höheren Arbeitsaufwand, den angesichts chronischer Ressourcenverknappung kaum noch eine Bibliothek aufzubringen im Stande ist. Möglicherweise wird man in Zukunft wenigstens die Titel des laufend in Fachzeitschriften, Jahrbüchern und Sammelwerken erscheinenden Schrifttums digital erfassen können – unter dem Kriterium der »Realität des Leistbaren«[35] kann diese Aufgabe retrospektiv wohl auch langfristig nur im Ausnahmefall erbracht werden. Das statistische Verhältnis zwischen selbst- und unselbstständigen Publikationen verdeutlicht das Problem: Repräsentiert die Titelaufnahme einer Monographie ungefähr 200 bis 300 Seiten, umfasst – gemäß den Erfahrungen von Compact Memory – ein Beitrag aus einem historischen Periodikum durchschnittlich kaum vier bis fünf Seiten Text. Ein Zeitschriftencorpus von circa 500.000 Seiten würde demnach die Erfassung von mehr als 100.000 Artikeln erforderlich machen, während im Fall von Monographien nur rund 2.000 Einträge anfielen.
Stellt die Erfassung unselbstständigen Schrifttums, die einem Standard wie zum Beispiel den »Regeln für die alphabetische Katalogisierung in wissenschaftlichen Bibliotheken« (RAK-WB) beziehungsweise den bislang nur als Entwurf vorliegenden »Regeln für die alphabetische Katalogisierung unselbstständiger Werke« (RAK-UW) folgen sollte, nicht eine herkulische Leistung dar? Ist es unter ökonomischen Gesichtspunkten überhaupt zu rechtfertigen, dass sich ein Bibliotheksteam über Jahre dieser Aufgabe widmet – wohl wissend, dass das Ergebnis nur einen Tropfen auf dem heißen Stein ausmacht? Lange vor Anbruch des digitalen Informationszeitalters wurde die Forderung laut, dass verstärkt auch unselbstständiges Schrifttum katalogisiert werden müsse. In den vergangenen Jahrzehnten übernahmen teilweise Fachbibliographien diese Aufgabe. Mitte der 1990er Jahre folgten entsprechende Internetangebote, die sich aus nahe liegenden Gründen zumeist auf die laufend neuerscheinenden, hauptsächlich naturwissenschaftlich-technischen Fachzeitschriften konzentrieren.[36] Die retrospektive Katalogisierung historischer Bestände ist hingegen sicher nicht grundlos immer wieder aufgeschoben oder nur im Einzelfall angegangen worden.
In diesem Zusammenhang lautet die zentrale Frage vor allem, ob sich die Mühe in Zeiten der zunehmend effizienter arbeitenden Texterkennungsprogramme überhaupt lohnt: Ohne Zutun eines Bibliothekars könnte ein umfangreiches Corpus von Grafiken automatisch texterkannt und in digitalen, das heißt recherchierbaren Volltext umgewandelt werden. Im Ergebnis differenzierte das System zwar nicht zwischen distinkten, bibliographischen Einheiten wie ›Autor‹, ›Titel‹ und so weiter, was eine – wiederum aufwändige – Nachindizierung der Texte voraussetzte. Der Nutzer wäre aber dennoch in der Lage, nach bestimmten Zeichenfolgen zu recherchieren – eben auch solchen, die zum Beispiel einen Autornamen oder den Titel eines gesuchten Beitrags repräsentieren.
Die Entscheidung, bibliographische Kerndaten manuell zu katalogisieren, bleibt unter wirtschaftlichen beziehungsweise technischen Gesichtspunkten stets anfechtbar. Man kann darüber spekulieren, ob künftig neue Technologien die klassische Form der Katalogisierung obsolet machen werden. Von dieser Entwicklung, die keinesfalls eine Zukunftsvision darstellt, einmal abgesehen, sind die neuen, hochinformativen Möglichkeiten jedoch an einem traditionellen Kriterium zu messen: Demzufolge basiert der ›Wert‹ eines digitalen Archivs nicht ausschließlich auf der Zweckmäßigkeit, die ein solches Angebot für einen bestimmten Nutzerkreis besitzt, wie im übrigen ja auch die Bedeutung einer traditionellen Bibliothek keinesfalls nur in der Literaturversorgung besteht. Gerade die »Erschließung alter und wertvoller Bestände«, die »von gesamtstaatlicher oder überregionaler Bedeutung« sind,[37] gilt zurecht als maßgebendes Förderkriterium, sofern dadurch der eigentliche Mehrwert jedes Einzelarchivs innerhalb der Verteilten Digitalen Forschungsbibliothek konstituiert wird. Den aus Einzelprojekten resultierenden Datenbanken ist folglich ein bleibender kulturhistorischer Stellenwert zu Eigen, der nicht unterschätzt werden kann: Wie ein Buch, das unkatalogisiert in eine Bibliothek eingestellt wurde, für den Nutzer schlichtweg nicht existiert, stellt erst die distinkte Titelaufnahme eines Zeitschriftenbeitrags die initiale Materialisierungsstufe seines potentiellen Informationsgehalts dar. Die Summe aller Titelaufnahmen bildet die Voraussetzung der optimalen Informationsvermittlung; der Zweck der Katalogisierung besteht indessen ebenso in der reinen Informationserhaltung. – Das Zukunftsszenario mag erschrecken, unrealistisch ist es keineswegs: Wenn die Originale eines Tages zu Staub zerfallen sind und einige Jahrzehnte oder Jahrhunderte später die archivierten Microfilme ausgebleicht sein werden, geben beizeiten konvertierte Datenbanken wenigstens darüber Auskunft, welche Informationen der Menschheit verloren gingen.
In den weltweit aktiven Jüdischen Studien muss die Titeldatenbank von Compact Memory zudem das Kriterium erfüllen, auch vom Grafik- beziehungsweise Volltextangebot unabhängige Recherchen zu ermöglichen. Als digitales ›Quellenverzeichnis‹ schließt die Datenbank die große Lücke zwischen biographischen Nachschlagewerken, Fachbibliographien sowie einschlägigen Lexika und Enzyklopädien, wobei der Vorteil darin besteht, dass die Daten online verfügbar sind – nötigenfalls auch auf anderen Plattformen, in fremden Informationsverbünden oder auch als Referenzorgan in Buchform. Dies setzt voraus, dass die bibliothekarischen Kerndaten standardisiert und vollständig katalogisiert werden, wobei die Dateneingabe – um die Masse halbwegs zu bewältigen – überregional erfolgen sollte und keine Redundanzen aufweisen darf.
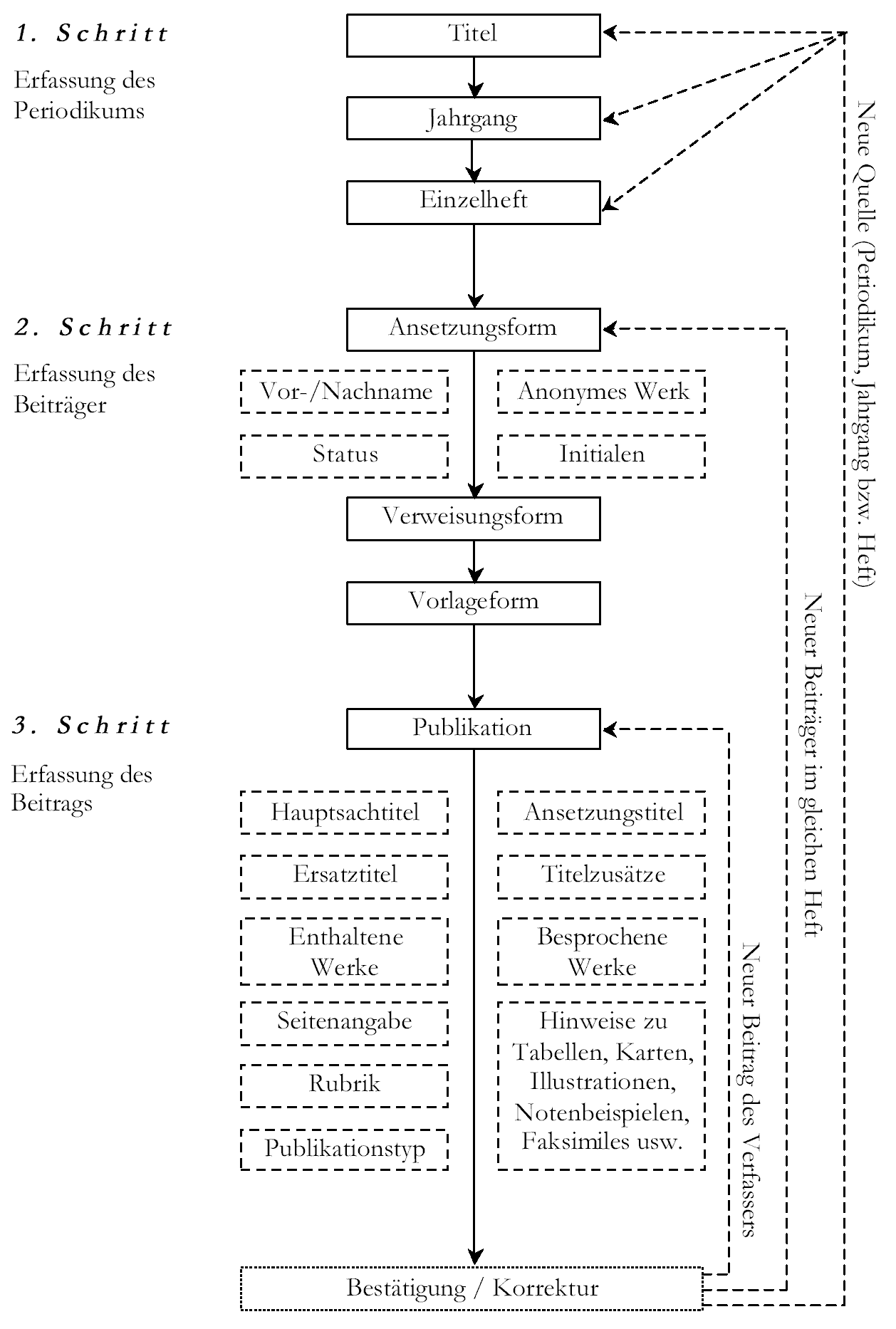
Abb. 4: Produktionsschema zur Erfassung bibliographischer Kerndaten
Die Erfassung der bibliographischen Kerndaten sieht laut Schema (siehe Abb. 4) drei aufeinander folgende Produktionsstufen vor, die mittels eines im Projekt entwickelten, webbasierten Eingabeinterfaces durchlaufen werden: Der Aufnahme des Periodikums folgt zunächst die Erfassung beziehungsweise Auswahl des Jahrganges und des Einzelheftes, dessen Beiträge katalogisiert werden sollen (siehe Abb. 5). Dem Eintrag dieser gestaffelten Quellenvermerke, die nur einmal vorgenommen werden müssen, um an allen Arbeitsstandorten abrufbar zu sein, schließt sich als zweiter Schritt die RAK-konforme Aufnahme der an der Publikation beteiligten Personen oder Körperschaften an.
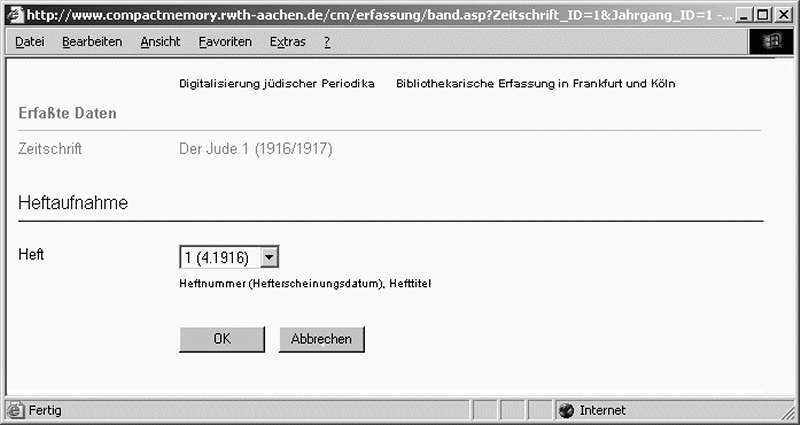
Abb. 5: Erfassung eines Zeitschriftenheftes
Die technische Realisation dieses Schritts stellte eine der komplexesten Aufgaben dar (siehe Abb. 6): Neben anonymen, nur mit Initialen versehenen oder von Körperschaften autorisierten Beiträgen müssen vor allem die im osteuropäischen Bereich häufig variierenden Namensschreibweisen berücksichtigt werden, ohne redundante Mehrfacheinträge für dieselbe Person zu erzeugen, welche die Homogenität des Datenmodells beeinträchtigen. In verschärfter Form tritt diese Problematik bei Pseudonymen zu Tage, die als solche vom Bibliothekspersonal oft nicht oder nur zufällig zu erkennen sind. Führt die ›Ansetzungsform‹ in der Regel den Geburtsnamen auf, geben die zugeordneten ›Verweisungsformen‹ die Pseudonyme oder wechselnden Namensschreibungen des Beiträgers wieder, wobei man die Angaben jederzeit separat erweitern oder Zuordnungen revidieren kann.
Der Bearbeiter muss ferner zur Aufnahme eines neuen Beiträgers alle bereits erfassten Ansetzungsformen sowie die zugehörigen Verweisungsformen durchsuchen können. Im Gegenzug galt es sicherzustellen, dass auch der Nutzer bei der Autorenrecherche eine vollständige Ergebnismenge der zugewiesenen Publikationen erhält – also auch diejenigen Artikel, die der Autor unter Pseudonym oder variierender Schreibweise seines Namens veröffentlichte. Da zudem zwei oder mehr Autoren beziehungsweise Körperschaften für einen Beitrag verantwortlich zeichnen können, muss die Personenerfassung beliebig oft wiederholbar sein, wobei es sich als sinnvoll erwies, den eventuell unterschiedlichen ›Status‹ der Urheber zu verzeichnen (Verfasser, Illustrator, übersetzer und so weiter). Der Datenbankserver, auf den die Clients zugreifen, verhindert auch bei diesem Arbeitsschritt redundante Doppel- oder Mehrfacherfassungen, da sämtliche Aufnahmen oder änderungen unmittelbar allen beteiligten Standorten zur Verfügung stehen.
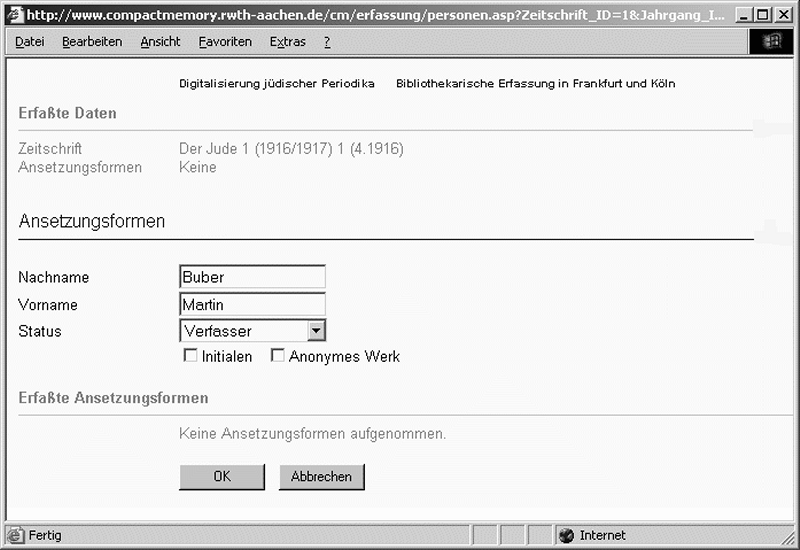
Abb. 6: Erfassung eines Zeitschriftenbeiträgers
Die Titelaufnahme schließt als dritter und letzter Produktionsschritt die Erfassung ab (siehe Abb. 7). Neben den Angaben zum Hauptsachtitel, zum Ansetzungstitel, einem eventuellen Ersatztitel oder diversen Titelzusätzen beziehungsweise obligatorischen Hinweisen zur Fundstelle (Rubrik, Seitenangaben) erschien es praktisch, die betreffenden Beiträge wenigstens ansatzweise zu verschlagworten: So werden im Fall von Rezensionen die besprochenen Werke in Kurzform verzeichnet; ebenso zentral für wissenschaftliche Recherchen, zum Beispiel für Fragen der Kanonbildung, ist die Möglichkeit, in Sammelbeiträgen enthaltene Werke, zum Beispiel Gedichte verschiedener Verfasser in einer Zeitschriftenanthologie, erfassen zu können. Die Treffermenge lässt sich darüber hinaus mit Hilfe des Publikationstyps (Beitrag, Rezension, Nachricht, Illustration und so weiter) oder der bereits zugewiesenen Rubrik (Leitartikel, Gemeindenachrichten, Feuilleton und so weiter) eingrenzen. Angaben zu Tabellen, Karten, Abbildungen, Notenbeispielen und so weiter liefern weitere Hinweise.
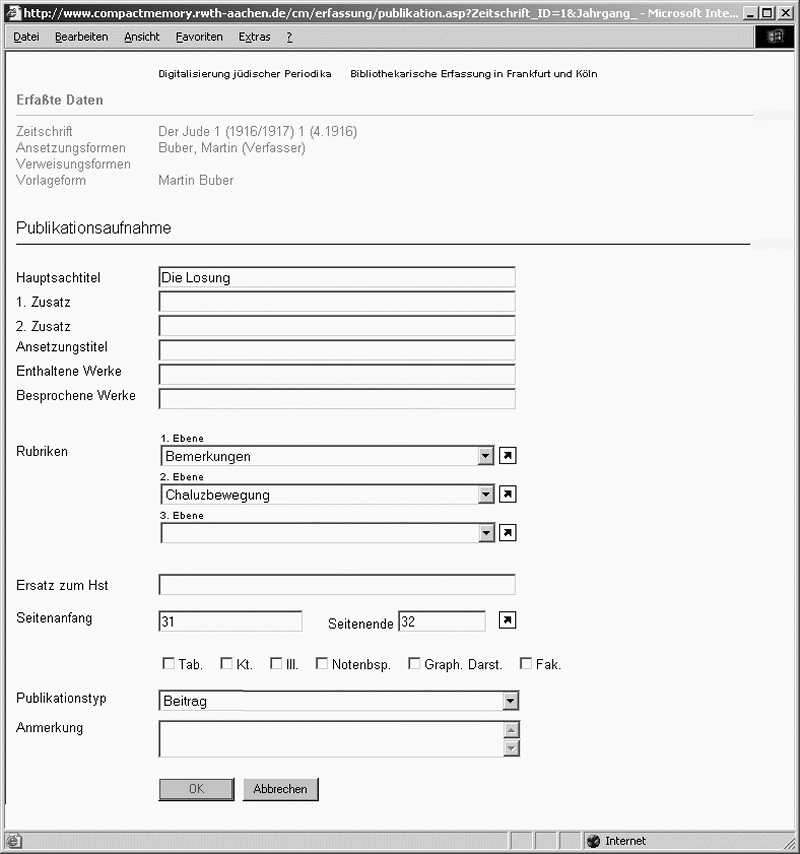
Abb. 7: Titelaufnahme
Bei der Entwicklung von Arbeitsoberflächen dieser Form und Funktionalität sind drei überlegungen von entscheidender Bedeutung: (1) In Anbetracht der großen Datenmengen müssen während der Katalogisierung jeglicher Zeitverlust vermieden und redundante Tätigkeiten neutralisiert werden. (2) Die Arbeiten dürfen an die Clients keine speziellen Hard- oder Softwareanforderungen stellen beziehungsweise den bibliothekarischen Nutzern keine tieferen technischen Kenntnisse abverlangen und müssen simultan von verteilten, das heißt letztlich beliebigen Standorten aus durchgeführt werden können. (3) Die erfassten bibliothekarischen Kerndaten sind dem Nutzer unmittelbar nach jeder einzelnen Titelaufnahme in strukturierter Form im Internet zur Verfügung zu stellen.
Wie angedeutet, wurde aus ökonomischen Gründen besonders das Prinzip der ›Rekursivität‹ berücksichtigt: Da das Bibliothekspersonal die Katalogisierung – von Nachträgen oder Korrekturen abgesehen – gemäß der Druckreihenfolge der Einzelbeiträge durchführt, ›merkt‹ sich das System das zuletzt aufgerufene Einzelheft, den übergeordneten Jahrgang sowie das zugehörige Periodikum. Der erste Produktionsschritt – die Erfassung des Periodikums, Jahrganges und Einzelheftes – ist gestaffelt, wodurch der Arbeitsaufwand minimiert wird: Die rekursiven Quellenangaben sind erst zu aktualisieren, wenn der Bearbeiter in ein neues Heft, einen neuen Jahrgang oder ein neues Periodikum wechselt. Die zentrale Verwaltung aller personen- und körperschaftsbezogenen Angaben, die nach einmaliger Erfassung an allen Standorten in Form von Auswahllisten zur Verfügung stehen, optimiert die Ergonomie und Effizienz des Produktionsverfahrens. Zugleich wird auf diesem Weg die einheitliche Datenerfassung und die Homogenität des Datenbestands gesichert – ein Faktor, dem vor allem in einem Projekt mit verteilten Standorten immense Bedeutung zukommt. Insgesamt konnten auf diese Weise innerhalb von knapp drei Jahren circa 60.000 Einzelbeiträge beziehungsweise rund 6.000 Personen- und Körperschaftsangaben katalogisiert und zur Recherche freigegeben werden (Stand: Januar 2004).
Ein webbasiertes Eingabeinterface mag im Vergleich zu einer fest am individuellen Arbeitsplatz installierten Softwarelösung einige Nachteile aufweisen. So sind zum Beispiel der technische Funktionsumfang und die ergonomischen Möglichkeiten eines lokalen Erfassungstools weniger limitiert, als dies bei einer Eingabeplattform der Fall ist, die über einen Internet-Browser angesteuert wird. Unter Umständen spricht jedoch gerade diese Alternative für ein Web-Interface: Die Datenbank kann nicht nur an jedem Ort der Welt genutzt werden – dies leistet auch jede moderne Erfassungssoftware –, die beteiligten Personen und Institutionen können vor allem ohne jedwede Anpassung ihres lokalen Systems arbeiten. Ein Wechsel des Rechnertyps, den eine Software eventuell voraussetzt, ist ebenso unnötig wie etwaige Umstellungen oder Aktualisierungen der individuellen Betriebssysteme. Die retrospektive Katalogisierung von Bibliotheks- und Archivbeständen kann mit Hilfe internetbasierter Eingabeinterfaces quasi voraussetzungslos von verteilten Standorten aufgenommen werden, wobei auch der anfallende Entwicklungs- und laufende Wartungsaufwand vergleichsweise gering wäre und keine Lizenzgebühren anfielen. Der Preis, der im Zuge einer solchen Entscheidung zu entrichten ist, besteht im Verzicht, alle in einem Projekt anfallenden Aufgaben auf einer integralen Plattform zu lösen. Grafiken und Volltexte mit einem Tool, bibliographische Kerndaten hingegen mittels einer Internetmaske in die Datenbank einzuspeisen, bedeutet, dass im Ergebnis kongruente Arbeitsabläufe separiert werden. Die später erforderliche Synthese der verschiedenen Datenmengen ist unter verfahrenstechnischen Aspekten selten ohne Reibungsverluste zu bewerkstelligen, wobei der vielleicht nur geringfügig höhere Arbeitsaufwand weniger schwer wiegt als die Preisgabe der technischen Homogenität und Effizienz.
Die Diskussion der Vor- und Nachteile, die eine konkrete technologische Fragestellung nach sich zieht, verdeutlicht einen entscheidenden Punkt: Digitalisierungsinitiativen stecken ein Terrain ab, auf dem gegenwärtig noch intensiv ›experimentiert‹ werden muss, um effiziente und verbindliche Produktionskonzepte zu entwickeln.[38] Digitalisierungsprojekte entwerfen, erproben und evaluieren Design- beziehungsweise Produktionsstrategien, um ihre Erfahrungen in einem langfristigen, nachhaltigen Digitalisierungsprogramm aufgehen zu lassen, welches den sukzessiven Aufbau »digitale[r] themenorientierte[r] Informationsnetze«[39] forciert und somit das Rückgrat des geplanten DFG-Portals »Sammlung digitalisierter Drucke« darstellen könnte. Dieses Experimentierfeld wurde in Compact Memory bewusst abgeschritten – die Entscheidung indessen, welche technische Alternative gewählt wird, basiert im Kern auf der Kompetenz und Bereitschaft der beteiligten Institutionen, neue, prototypische Technologien in bestehende Systeme zu integrieren, um dadurch den Aufbau benutzerorientierter Informations-Infrastrukturen voranzutreiben.
Welche Produktionsvariante im skizzierten Fall letzten Endes bevorzugt wird, hängt einerseits von den ins Auge gefassten Projektzielen, von den verfügbaren Ressourcen und nicht zuletzt von der technologischen Kompetenz des Mitarbeiterstabs ab. Andererseits verdeutlichen die Ausführungen zur bibliothekarischen Datenerfassung, dass die gewählte Lösung dem Gebot der ökonomie zu folgen hat und die Datenbasis migrationstauglich sein muss, um weltweit in Form überregionaler, internationaler Gateways einen standardisierten Zugang zu ermöglichen.[40]
Im Allgemeinen interessiert es den Nutzer nicht, auf welche Weise Daten in eine Datenbank gelangen – entscheidend ist für ihn, wie das erfasste Material aufbereitet und im Internet zur Verfügung gestellt wird. Dabei erweist sich der Grad, in dem das Corpus in formaler und inhaltlicher Hinsicht erschlossen wurde, als ebenso zentraler Faktor wie die ergonomische und taktile Funktionalität der Zugriffsmöglichkeiten. Die Attraktivität eines digitalen Archivs steigt folglich in dem Maß, wie es den individuellen Arbeitsgewohnheiten seiner Nutzer entgegenkommt und traditionelle Wege der Informations- und Literaturbeschaffung erleichtert.
Von der Volltextsuche abgesehen, sind es im Fall der bibliographischen Recherche in einem digitalen Zeitschriftencorpus im Wesentlichen drei typische Suchstrategien, welche die Anbieter berücksichtigen müssen: In der Regel will der Nutzer über gängige Suchoptionen gezielt und ohne Verzug bestimmte Materialien aufrufen, deren Quellenangaben ganz oder teilweise bekannt sind (Simple Search). Will man Suchergebnisse einschränken oder liegen nur rudimentäre Hinweise vor, müssen mittels kombinierter Suchmöglichkeiten hierarchisch organisierte Trefferlisten generiert werden können (Advanced Search). Zuletzt darf nicht ignoriert werden, dass viele Nutzer im Bestand ›stöbern‹ möchten: Wie der Besucher einer realen Bibliothek mal zu diesem, mal zu jenem Band greift, klickt der Nutzer eines digitalen Archivs mal diesen, mal jenen Link an, um sich von Zufallsfunden überraschen zu lassen oder in bekannten Kontexten gezielt zu lesen.
Es empfiehlt sich daher grundsätzlich, dass ein digitales Archiv seinen gesamten Datenbestand in strukturierter Form visualisiert – vor allem um den Nutzern einen überblick über den Umfang, die Vollständigkeit und die Erschließungstiefe des Textcorpus zu vermitteln. Endloslisten, die bibliographische Daten nach singulären Kriterien aufführen, erweisen sich als unpraktisch und unübersichtlich. Dagegen wird der Einstieg zweifellos erleichtert, wenn das Vorwissen der Nutzer bezüglich des Umgangs mit bestimmten Textcorpora berücksichtigt wird und die Präsentation des digitalen Bestands der analogen ›Urform‹ des Mediums folgt: Aus Erfahrung ›weiß‹ der Nutzer, dass er in einer Bibliothek zunächst ein Periodikum auswählt und dann zu einem bestimmten Jahrgang greift. Er hat ›gelernt‹, dass ein Jahrgang eventuell ein Inhaltsverzeichnis enthält, auf jeden Fall aber eine beliebige, prinzipiell chronologisch geordnete Anzahl Einzelhefte umfasst; erst in den Heften erwartet der Nutzer, auf ›Text‹ in Form einzelner Artikel zu stoßen.
Der Medienwechsel muss nicht notwendigerweise eine Umstellung internalisierter Gewohnheiten beziehungsweise praxiserprobter Strukturierungsformen bedeuten: Ein digitales Archiv sollte dieses erworbene Vorwissen vielmehr kreativ umsetzen und dem Nutzer – neben diversen Suchfunktionen – stets auch den intuitiven, sozusagen ›plastischen‹ Zugriff auf das Textcorpus ermöglichen. Dementsprechend wurde in Compact Memory eine Präsentationslösung angestrebt, die die Recherche, Navigation und Orientierung im Corpus erleichtert, indem alle Daten mit Hilfe des Library Scouts bis in die Einzelhefte hinein visualisiert werden (siehe Abb. 8).
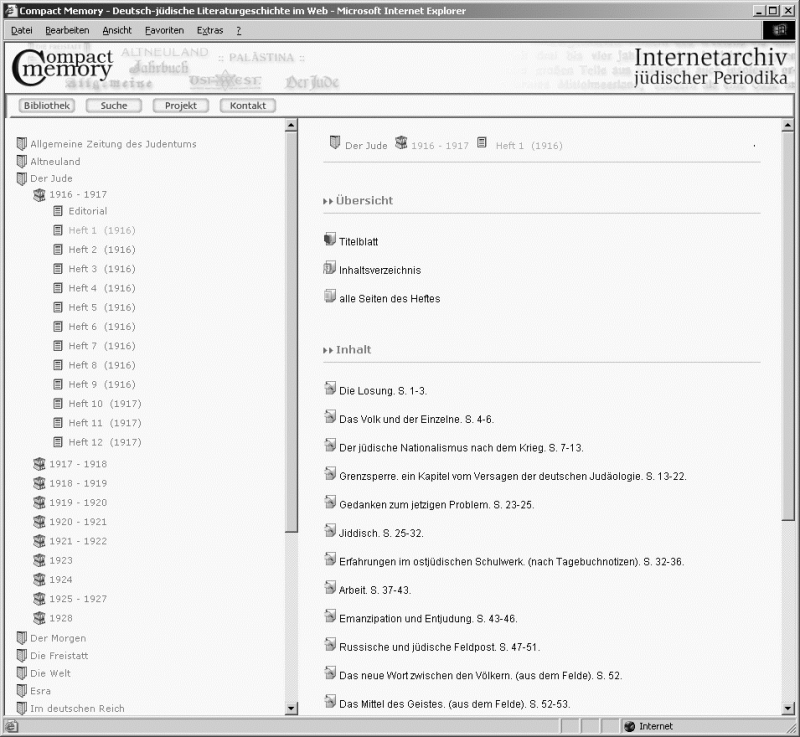
Abb. 8: Anzeige des Inhalts eines Einzelheftes
Gegenüber der Titelrecherche bildet die Volltextsuche einen logisch und arbeitsteilig weitgehend eigenständigen Aufgabenbereich, der im Anschluss an die Präsentation der Digitalisate und die Erfassung bibliographischer Kerndaten die dritte, separate Produktionsstufe darstellt. Die Problematik ist allgemein bekannt: Nur in seltenen Fällen lässt sich vom Titel eines Beitrags auf dessen Inhalt oder historischen Stellenwert schließen; bedeutende Beiträge tragen ausdrucksschwache überschriften oder können von mehr oder minder unbekannten Verfassern stammen. Fördert die Suche nach Titelschlagworten also stets ein Konglomerat relevanter und peripherer Angaben zu Tage, vermag erst die Volltextrecherche die Spreu vom Weizen zu trennen, indem die Textinhalte nach bestimmten Zeichenfolgen durchsucht und statistisch aufbereitete Trefferlisten generiert werden.
Die Umwandlung der Grafiken in Volltexte bedeutet einen erheblichen Mehraufwand, auch wenn dieser Arbeitsschritt mit Hilfe automatisierter OCR-Software durchgeführt wird. Zwar sind Texterkennungsprogramme heute deutlich leistungsstärker, leichter zu handhaben und preiswerter als vor einigen Jahren. In einem für die retrospektive Digitalisierung zentralen Punkt stoßen aber auch beste OCR-Programme an ihre Grenzen: Kann Schrift in Antiqua, gute Vorlagenqualität vorausgesetzt, in der Regel mit Trefferquoten von annähernd 100 Prozent erkannt werden, erfordert die bis in die 1920er Jahre im deutschen Sprachraum weit verbreitete Frakturschrift bislang einen beträchtlichen manuellen Trainingsaufwand, um halbwegs zufrieden stellende Ergebnisse zu erzielen. Die fortschreitende OCR-Entwicklung wird hier über kurz oder lang Abhilfe schaffen, vor allem sobald die Softwareindustrie dieses Marktsegment entdecken sollte. Bis dahin wird jedes Digitalisierungsprojekt individuell zu entscheiden haben, ob der zu erbringende Aufwand in einem vertretbaren Verhältnis zum Nutzen steht, wodurch letztlich immer auch die Corpusauswahl betroffen ist.
So zentral wie die Frage nach der erzielbaren Qualität der Volltexte ist das Problem, wie man die enorme Quantität an Text auf ökonomische Weise bewältigt. Allein aus Gründen der Ergonomie und übersichtlichkeit können mehrere zehn- oder hunderttausend Seiten nicht einfach einem separat arbeitenden OCR-Programm zugeführt und im Anschluss manuell in eine Datenbank überführt werden. Die Einspeisung der Grafiken in das hierarchisch strukturierte Verzeichnissystem und die Zuweisung der seitenweise erzeugten Volltexte sind vielmehr als logisch parallel laufende Produktionsstufen zu organisieren. Zur Vermeidung von Reibungsverlusten sollte es demnach möglich sein, die Erfassung der Grafiken und die Erzeugung beziehungsweise Verknüpfung der zugehörigen Volltexte nicht von getrennt arbeitenden Programmen, sondern auf einer integralen Plattform durchzuführen.
Der in Compact Memory eingesetzte Library Manager wurde zu diesem Zweck um ein OCR-Modul erweitert,[41] das einen auszuwählenden Bestand von Grafiken – komplette Periodika, bestimmte Jahrgänge, einzelne Hefte oder Seiten – in Stapelverarbeitung in digitalen Text überführt. Die resultierenden Textdateien werden in der Datenbank automatisch den entsprechenden Grafiken zugeordnet und stehen unmittelbar der Volltextrecherche zur Verfügung. Der Library Manager bietet ferner alle zentralen Funktionen des OCR-Programms, darunter die Möglichkeit, besondere Zeichensätze wie Fraktur zu trainieren. Mit Hilfe des integrierten Editors können die vorliegenden Texte darüber hinaus nach Bedarf redigiert sowie TEI-konform im XML-Format ausgezeichnet werden.[42]
Der vorliegende Werkstattbericht versuchte anhand konkreter Erfahrungen und Fragestellungen, die im Zuge der digitalen Zeitschriftenreformatierung auftreten, ein Produktionskonzept zu skizzieren, dessen Schwerpunkt in der verzugsfreien, halbautomatisierten und standardisierten Massendigitalisierung historischer Drucke besteht. Vor allem der souveräne Umgang mit heute verfügbaren Technologien zur Massendigitalisierung bildet die Voraussetzung, eine Zukunftsvision zu verwirklichen, die auch verantwortliche Institutionen nicht mehr hinter vorgehaltener Hand diskutieren:
Der insgesamt – auch international – erreichte Stand der retrospektiven Digitalisierung lässt jedoch heute die Vision realistisch erscheinen, dass in einer oder zwei Generationen die gesamten historischen Buchbestände des Landes, ergänzt durch entsprechende Digitalisate handschriftlicher, bzw. nichtschriftlicher Teile des kulturellen Erbes über eine einheitliche Oberfläche vom Schreibtisch jedes und jeder Interessierten direkt und ohne nennenswerte Zeitverzögerung zugänglich sein könnten. Auch eine konservative Hochrechnung technischer Entwicklungen lässt erwarten, dass ein derartiges Ziel in einigen Jahrzehnten erreicht werden kann.[43]
Ausländische Großinitiativen,[44] aber auch viele prototypische Lösungen deutscher Einzelprojekte demonstrieren, dass dieser gleichsam enzyklopädische Auftrag heute bereits zu bewältigen ist. Die Hürden, die im Verbund deutscher Bibliotheken, Archive und Universitäten noch genommen werden müssen, sind weniger technischen als organisatorischen Ursprungs. Drei Aspekte stehen dabei im Vordergrund: (1) Schaffung eines zentralen Internet-Portals, das einen fachübergreifenden Zugriff auf vorhandene digitale Drucke ermöglicht; (2) Synchronisation und Evaluation laufender beziehungsweise zukünftiger Digitalisierungsprojekte auf Basis eines zu erstellenden, verbindlichen ›Kriterienkatalogs‹; (3) Planung und Prioritätensetzung der Digitalisierung historischer Bibliotheks- und Archivbestände im Rahmen eines nationalen Gesamtkonzepts.[45]
In Erweiterung der so genannten Sondersammelgebiete stellt das Konzept der Virtuellen Fachbibliothek zweifellos die wichtigste Alternative dar, potentielle Nutzer mittels »qualitätsgesicherte[r] Erschließungs- und Zugangssysteme« über einschlägige Ressourcen wie digitale Sammlungen zu informieren.[46] Angesichts der zunehmenden Spezialisierung der Einzelwissenschaften ist vor allem die Virtuelle Fachbibliothek das probate Mittel, »dem Benutzer einen einigermaßen umfassenden Nachweis der in Deutschland verfügbaren digitalen Bestände geben und ihm den Zugriff darauf ermöglichen« zu können.[47] Ebenso unerlässlich wie die einheitliche Anwendung technischer und methodischer Standards, welche die nachhaltige Nutzung solcher Gesamtsysteme garantieren, erfordert der Aufbau Virtueller Fachbibliotheken die Synthese von bibliothekarischer, fachwissenschaftlicher und technologischer Kompetenz. Allein die aktive Zusammenarbeit zwischen Informationsanbietern, Nutzern und Systemkonstrukteuren kann ein Angebot schaffen, das die Interessen aller Beteiligten zu berücksichtigen vermag.
Dem weltweit aktiven Forschungszweig ›Jüdische Studien‹ würde eine nationale wie internationale Initiativen synchronisierende Fachbibliothek unschätzbare Dienste leisten. Eine solche Virtuelle Forschungsbibliothek wäre in der Lage, sämtliche Zeugnisse jüdischer Tradition in sich zu vereinen – historische, literarische und wissenschaftliche Primärtexte, musikalische oder grafische Quellen sowie Nachlässe jedweder Provenienz. Darüber hinaus könnten Enzyklopädien, Nachschlagewerke, Bibliographien, Kataloge und Verzeichnisse, aber auch Wörterbücher und Periodika zur Verfügung gestellt werden. Die hierzu erforderlichen, international kooperierenden Initiativen besäßen in der Forschungsbibliothek aber nicht nur einen virtuellen ›Lesesaal‹. Sie bildeten eine globale Plattform, die einerseits der Erfassung und Verbreitung von benötigten Textcorpora dient. Andererseits entstünde ein Forum zur Präsentation von Forschungserträgen und -initiativen, das weitaus aktueller als herkömmliche Printmedien sein könnte.
Till Schikcketanz/Kay Heiligenhaus (Aachen)
Till Schicketanz, M.A.
(24. März 2004)
Lehr- und Forschungsgebiet Deutsch-jüdische Literaturgeschichte
Germanistisches Institut der RWTH Aachen
Templergraben 55
52056 Aachen
schicketanz@compactmemory.de
Kay Heiligenhaus, M.A.
Semantics Kommunikationsmanagement GmbH
Theaterstraße 106
52062 Aachen
heiligenhaus@semantics.de