Das Projekt 'Westmitteldeutsche und ostfranzösische Urkunden- und Literatursprachen im 13. und 14. Jahrhundert (Germanistik) hat sich zum Ziel gesetzt, das Aufkommen der deutschen Urkundensprache im Gebiet zwischen Maas und Rhein von seinen Anfängen bis ca. 1330 systematisch zu erfassen sowie die regionalen Varietäten zu beschreiben. Die derzeitige Gesamtquellenbasis besteht aus annähernd 500 Originalausfertigungen. Die deutschsprachigen Urkunden des 13. Jahrhunderts sind im von Friedrich Wilhelm begründeten 'Corpus der altdeutschen Originalurkunden bis zum Jahr 1300' vorbildlich ediert und mit ihren historischen Umfelddaten durch Regesten und Register erschlossen. Dagegen sind die Urkunden des 14. Jahrunderts häufig unediert oder nur in älteren, sprachwissenschaftlich ungenügenden Editionen greifbar. Daher sollen diese Urkunden ediert und für Germanisten und Historiker gleichermaßen aufbereitet werden. Dabei werden neben einer Buchedition die Möglichkeiten ausgeschöpft, die eine elektronische Publikation bietet: Das Urkundenkorpus läßt sich in einer internetbasierten Recherche nach bestimmten Kategorien durchsuchen. Der Text selbst wird nicht allein mit verschiedenen Erschließungsinstrumenten direkt verknüpft, sondern über einen lemmatisierten Index auch mit dem elektronischen Verbund mittelhochdeutscher Wörterbücher vernetzt. Alle Arbeitsschritte und Komponenten der Edition werden mit dem Tübinger Programmpaket TUSTEP realisiert.
Der Beitrag gliedert sich in drei thematische Blöcke: Zunächst wird die inhaltliche Seite sowie die Zusammenstellung des Trierer Korpus vorgestellt, anschließend die Konzeption der elektronischen Publikation erläutert und schließlich die technische Umsetzung angesprochen.
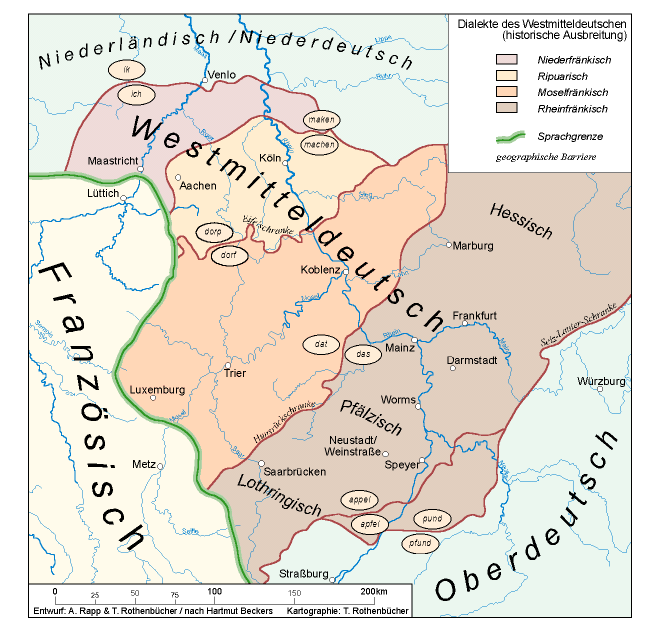
Das Trierer Korpus mittelfränkischer Urkunden des 14. Jahrhunderts ist entstanden im Rahmen der interdisziplinären Arbeiten des Teilprojekts D7 Westmitteldeutsche und ostfranzösische Urkunden- und Literatursprachen im 13. und 14. Jahrhundert (Germanistik), das seit 1990 unter dem Dach des historischen Sonderforschungsbereichs 235 Zwischen Maas und Rhein. Beziehungen, Begegnungen und Konflikte in einem europäischen Kernraum von der Spätantike bis zum 19. Jahrhundert an der Universität Trier angesiedelt ist.[1] Das Projekt hat sich zum Ziel gesetzt, das Aufkommen der deutschen Urkundensprache zwischen Maas und Rhein von seinen Anfängen, das heißt ab der zweiten Hälfte des 13. Jahrhunderts, zu erfassen sowie die regionalen Varietäten zu beschreiben. Die Zusammenstellung des Urkundenkorpus erfolgte daher nach sprachwissenschaftlichen Kriterien.
Die derzeitige Gesamt-Quellenbasis des Urkundenprojekts besteht aus annähernd 500 Originalausfertigungen. Ausgewählt sind deutschsprachige Urkunden, die relevant sind für Herrschaften, Städte, Institutionen und Einzelpersonen des anhand sprachwissenschaftlicher Kriterien konstituierten Untersuchungsraums, der – mit unterschiedlichen Schwerpunkten – das Westmitteldeutsche der Kulturräume Köln, Trier, Luxemburg und Mainz berücksichtigt.
Abbildung 1: Der westmitteldeutsche Sprachraum
Für den Zeitraum zwischen 1248 und 1330 wurden westmitteldeutsche beziehungsweise ab 1300 in der Hauptsache mittelfränkische Urkunden systematisch und möglichst vollständig erschlossen. Über diesen Zeitraum hinaus, bis circa 1350, wurden wegen des enormen Anstiegs volkssprachigen Geschäftsschrifttums nurmehr bestimmte Serien und Einzelstücke ausgewählt, die vor allem der Abrundung des Korpus dienten. So sollten einerseits Schreiberserien oder inhaltlich-thematisch zusammengehörige Urkunden nicht auseinandergerissen werden, andererseits chronologisch der Anschluß an die Arbeiten zur Grammatikographie des Frühneuhochdeutschen, die mit 1350 einsetzen, gewährleistet bleiben.
Warum ist die Zusammenstellung mittelfränkischer Quellen der mittelhochdeutschen Sprachperiode notwendig und warum wurden gerade Urkunden als Quelle für sprachgeschichtliche Untersuchungen gewählt?
• Weil die mittelfränkischen, insbesondere die moselfränkischen Schreibsprachen des 13. und 14. Jahrhunderts in den einschlägigen Grammatiken und Handbüchern zum Mittelhochdeutschen unzureichend dokumentiert sind. Literarische Quellen und Handschriften aus diesem Raum sind rar. Die Eruierung und Zusammenstellung geeigneter mittelfränkischer Quellen sowie ihre Erschließung, Beschreibung, Einordnung und Bereitstellung sind daher ein dringendes Desiderat der Grammatikographie und Schreibsprachgeschichte des Mittelhochdeutschen.[2]
• Weil urkundliche Quellen aufgrund der zahlreichen situativen Umfelddaten für sprachwissenschaftliche Auswertungen besonders günstige Voraussetzungen bieten. Urkunden sind in der Regel datiert und zum Teil auch lokalisiert beziehungsweise aufgrund der situativen Verankerung gut lokalisierbar. Ferner sind die am Schreibakt beteiligten Personen, die Adressaten, bekannt, in Glücksfällen sogar die Schreiber selbst. Schließlich handelt es sich bei Originalurkunden um »Autopgraphe«, nicht um Abschriften, die Sprachmischungen mit sich bringen.
Für das 13. Jahrhundert konnte auf das von Friedrich Wilhelm begründete Corpus der altdeutschen Originalurkunden bis zum Jahr 1300[3] zurückgegriffen werden. Das bedeutete, nicht allein über eine für sprachwissenschaftliche Belange vorzüglich geeignete Edition zu verfügen, sondern ebenso über eine Reihe von Hilfs- und Findmitteln, die für die Arbeit mit Urkunden unerläßlich sind. Neben Regesten zu den einzelnen Urkunden bietet das Corpus ein Archivregister sowie ein Orts- und ein Personenregister. Zusätzlich ist das im Entstehen begriffene, derzeit bis zum Buchstaben »M« fertiggestellte Wörterbuch der mittelhochdeutschen Urkundensprache verfügbar. Ferner steht das Schreibortverzeichnis zum Corpus zur Verfügung. Unter diesen Voraussetzungen waren für das 13. Jahrhundert 124 Urkunden aus dem Untersuchungsraum zu ermitteln.[4]
Für das 14. Jahrhundert stand kein dem Wilhelmschen Corpus vergleichbares Werk zur Verfügung. Anhand von Recherchen in den regional relevanten Archiven sowie Sichtung der einschlägigen Quellenpublikationen konnten für den Zeitraum von 1300 bis 1330(-1350) rund 350 Urkunden nachgewiesen werden. Diese Sammlung stellt das oben genannte Trierer Korpus dar. 212 der Stücke liegen derzeit in Abbildungen der Originale und diplomatischen Transkriptionen vor. Während also für die Zusammenstellung des Materials der Mangel an Arbeits- beziehungsweise Findinstrumenten kompensiert werden konnte, ist eine angemessene Bearbeitung der Urkunden des 14. Jahrhunderts unter diesen Voraussetzungen nicht zu leisten. Es gilt also, zum einen das Korpus des 14. Jahrhunderts zu edieren, zum andern mit entsprechenden Erschließungsinstrumenten auszustatten. Dabei soll das Material gemäß dem interdisziplinären Ansatz des Projekts für Historiker und Germanisten möglichst umfassend, flexibel und vielfältig nutzbar bereitgestellt und langfristig gesichert werden.
Bei den Arbeiten im Projekt stellte die EDV von Anfang an ein grundlegendes Arbeitsinstrument dar. Neue Wege beschreitet das Projekt nun in der Nutzung des Computers nicht mehr allein als Werkzeug, sondern auch als Medium zur Darstellung der Materialien und Ergebnisse in elektronischer Form. Gerade für die Edition und Erschließung von Textsammlungen aller Art bieten sich die Möglichkeiten der neuen Medien besonders an. Das Spezifische eines – gleich nach welchen Kriterien zusammengestellten – Urkundenkorpus liegt darin, daß es sich aus zahlreichen Einzeltexten zusammensetzt, die auf verschiedenen Ebenen in ein komplexes Beziehungsgeflecht eingebunden sind. Diese Struktur kann anhand der ergonomischen Aufbereitung und der nichtlinearen Präsentation im EDV-Medium für den Benutzer ideal transparent und handhabbar gemacht werden, denn sie ermöglicht die Herstellung ›beliebiger‹ struktureller Zusammenhänge.
Abbildung 2: Startseite der elektronischen Probepublikation
Um das neuartige Konzept frühzeitig zur Diskussion zu stellen, wurde eine Probepublikation von sechs Urkundenausfertigungen im Internet zur Verfügung gestellt.[5] Die weitere Planung sieht vor, die einzelnen Komponenten der elektronischen Publikation sukzessive zu vervollständigen. Bei den augenblicklichen Entwicklungen auf dem Gebiet der Informationstechnologie sowie dem Stand der wissenschaftlichen Diskussion scheint es ratsam, auch Teilergebnisse bereits in einem frühen, durchaus noch unfertigen Stadium zugänglich zu machen, um bereits in der Ausarbeitungsphase in die Diskussion einzutreten und Rückmeldungen und Hinweise zu erhalten.
Drei Zugriffsmöglichkeiten auf das Textmaterial und die Erschließungsinstrumente sowie seit September 1999 eine erste vorläufige Version der Recherchemaske zur noch unfertigen Kontextdatenbank werden bislang in der ›Vorabpublikation‹ exemplarisch vorgestellt. Im folgenden werden zunächst die einzelnen Komponenten erläutert, bevor auf die technische Realisierung eingegangen wird.
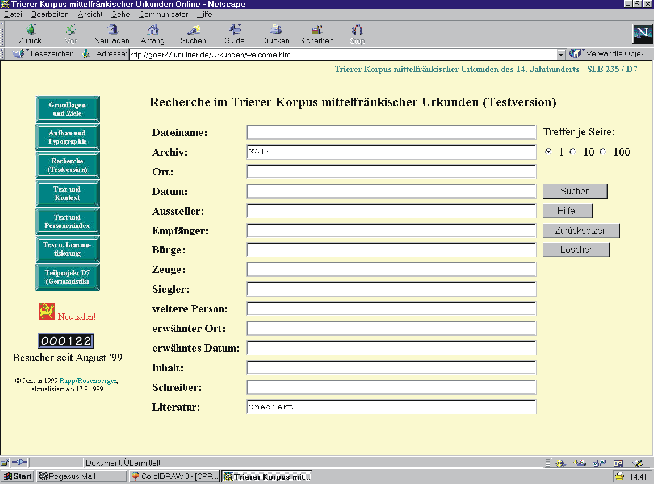
Abbildung 3: Internet-Suchmaske zum Trierer Korpus (Testversion)
Mittels einer Suchmaske kann die Mehrzahl der Kategorien, die im grundlegenden Erschließungsinstrument, der Kontextdatenbank (dazu unten mehr), berücksichtigt worden sind, recherchiert werden. Folgende Kategorien sind in die Maske aufgenommen:
|
• Dateiname/Kennung |
• Empfänger |
• erwähnter Ort |
|
• Archivsignatur |
• Bürge |
• erwähntes Datum |
|
• Ausstellungsort |
• Zeuge |
• Inhalt |
|
• Ausstellungsdatum |
• Siegler |
• Schreiber |
|
• Aussteller |
• weitere Person |
• Literatur |
Zu den einzelnen Kategorien ist folgendes zu bemerken:
Dateiname/Kennung: In der eindeutigen Kennung[6] ist das Tagesdatum der Urkunde abgelegt. Da sich der Zeitraum des Korpus von 1300 bis 1330(50) erstreckt, kann die Jahrhundertangabe wegfallen. Vor der Ziffernfolge steht immer ein x. Die Urkunde mit der Kennziffer x001210 ist also am 10. 12. 1300 ausgestellt.[7] Diese eindeutige Kennung für jede Urkundenausfertigung bildet die Referenz für alle Erschließungsinstrumente. Ist das Feld in der Datenbank noch leer, wurde diese Urkunde (noch) nicht transkribiert.
Archivsignatur (vollständig): Dieses Feld ist für alle 356 Urkunden des Trierer Korpus vollständig nachgewiesen. Dies ist also im Augenblick der sicherste Zugriff auf die deutschsprachigen Urkunden des mittelfränkischen Raums.
Ausstellungsort (vollständig): Auch dieses Feld ist für die 212 transkribierten Urkunden vollständig, das heißt alle genannten Ausstellungsorte wurden identifiziert und die modernen Namenformen angegeben. Ein Ausstellungsort wird jedoch vergleichsweise selten genannt (44 Fälle).
Ausstellungsdatum (vollständig): Das Feld »Ausstellungsdatum« zählt ebenfalls zu den für das Gesamtkorpus bereits vollständig ermittelten Kategorien. Die Angabe des Datums erfolgt in der Reihenfolge Jahr – Monat – Tag, also zum Beispiel 1300 XII 10, sofern das vollständige Tagesdatum vorhanden ist. Das Ausstellungsdatum ist – wie bereits erwähnt – abgelegt im Dateinamen und dient als eindeutige Kennung für jede Urkunde.
Aussteller (unvollständig): In diesem Feld werden die formalen Aussteller der Urkundenausfertigung identifiziert. Nicht nur Personen, auch Städte oder Institutionen können als formale Aussteller fungieren. Dies gilt auch für die weiteren Funktionsträger des Rechtsgeschäfts. Zum Teil werden über die Identifizierung hinausgehende Informationen gegeben. Die Ermittlung und Vervollständigung dieser und der folgenden Kategorien steht noch am Beginn und wird einen Arbeitsschwerpunkt des Projekts für die nächste Phase darstellen. Bei (›vorläufig‹) sicheren Identifizierungen finden sich hier die modernen Namenformen; ansonsten die historischen, zur Unterscheidung kursiv gesetzten Schreibungen aus der Urkunde selbst.
Empfänger/Zeuge/Bürge/Siegler (unvollständig): Auch hier gilt das zum Feld »Aussteller« Gesagte.
Erwähnte Person (unvollständig): In diesem Feld sind Personen kategorisiert, die bei dem eigentlichen Urkundsgeschäft nicht als Funktionsträger beteiligt sind, aber in der Urkunde Erwähnung finden.
Erwähnter Ort (unvollständig): In dieser Kategorie werden mit Ausnahme des Ausstellungsortes alle Orte im weitesten Sinne, also auch Burgen, Klöster oder Flüsse beispielsweise, identifiziert.
Erwähntes Datum (unvollständig): In diesem Feld werden alle Daten mit Ausnahme des Ausstellungsdatums bestimmt.
Inhalt (unvollständig): In diesem Feld wird das Rechtsgeschäft zum einen mit einem standardisierten Schlagwort[8] beschrieben, zum andern ausführlicher dargestellt.
Schreiber (unvollständig): Dieses Feld enthält Händezuweisungen und Schreiberidentifizierungen. Es ist im Augenblick noch weitgehend ungefüllt.
Literatur (unvollständig): Die Literatur zur jeweiligen Urkunde ist aufgegliedert und gekennzeichnet nach ›Edition, Regest, Literatur‹. Aufgenommen ist ebenfalls, wenn die Urkunde bislang in der Literatur weder durch eine Edition noch durch ein Regest bekannt war; in diesem Fall ist der Begriff ›unediert‹ vermerkt.
Aus dem hier zu den einzelnen Kategorien dargelegten wird deutlich, daß es sich noch um eine vorläufige Anwendung zu Testzwecken handelt. Die Suchmöglichkeiten sind daher noch sehr eingeschränkt. Ziel für die endgültige Version ist es, die einzelnen Kategorien unter- und miteinander verknüpfbar zu machen, um elaborierte Suchanfragen formulieren zu können. Einen weiteren wichtigen Fortschritt für die Recherchemöglichkeiten wird die Integration der Abfrage nach Lemmata bringen, die baldmöglichst realisiert werden soll.
Von der Suchmaske gibt es eine direkte Verknüpfung zur elektronischen Version des Urkundentextes selbst, die über die eindeutige Kennung jeder Urkunde funktioniert.
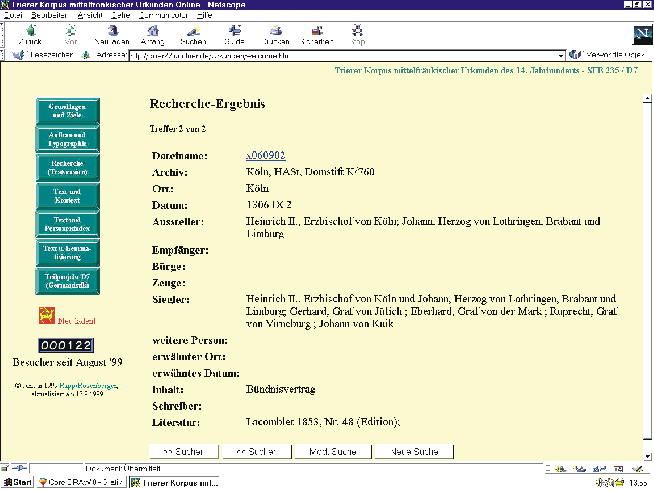
Abbildung 4: Recherche-Ergebnis mit Link zur elektronischen Urkundenpublikation
Im Feld »Dateiname/Kennung« kann diese als Link zum Text selbst angewählt werden, sofern die elektronische Version dieser Urkunde (bislang also sechs Texte) zur Verfügung steht. Man gelangt in die Zugangsform »Text und Kontext«, die im folgenden beschrieben wird.
Jeder der zur Zeit realisierten Zugänge ist so konzipiert, daß der Bildschirm in drei Felder aufgeteilt ist. Am oberen Bildschirmrand befindet sich eine feststehende Titelzeile, die ferner einen Link zur »Leitseite« und damit zu den übrigen Zugängen bietet. Darunter ist der Bildschirm in zwei Kolumnen aufgeteilt: Im linken Feld befindet sich bei allen drei Zugängen der Urkundentext in diplomatischer Transkription, im rechten Feld parallel dazu das jeweilige angewählte Erschließungsinstrument. Die chronologisch angeordneten[9] Urkundentexte werden mit der oben erläuterten eindeutigen Kennung überschrieben, die sich aus dem Ausstellungsdatum ergibt. Mit dieser vollständigen Datumsreferenz ist jede dem Zeilenfall der Originalurkunde entsprechende, durchnumerierte Zeile der Transkription versehen, so daß auch beim Scrollen eine Orientierung gewährleistet bleibt.
Die Felder sind jeweils in beiden Richtungen miteinander verknüpft, das heißt man gelangt sowohl aus der farbig hervorgehobenen Stelle der Urkundentranskription in das Informationsfeld als auch umgekehrt aus diesem Feld anhand der Zeilenreferenzen an die entsprechende Textstelle.
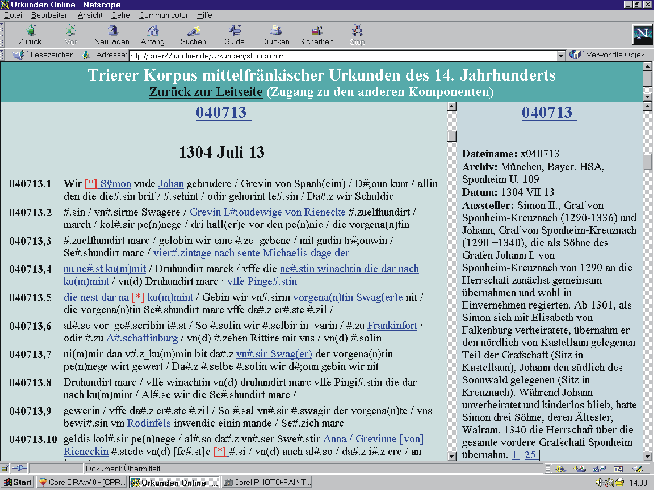
Abbildung 5: Elektronische Publikation des Trierer Korpus – »Text und Kontext«
In der Kontextdatenbank sind die diplomatischen, historischen und bibliographischen Kontextinformationen zu jeder einzelnen Urkunde in einem festgelegten Kategorienkatalog systematisch erfaßt, der den oben vorgestellten Feldern der Recherchemaske entspricht.
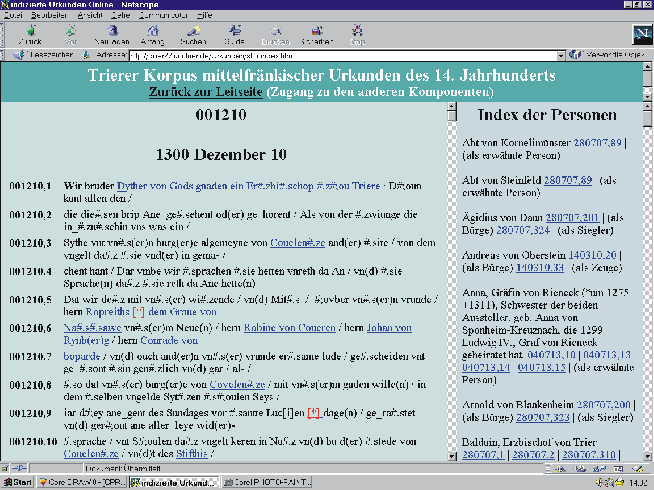
Abbildung 6: Elektronische Publikation des Trierer Korpus – »Text und Index«
Der zweite Zugang verknüpft den Text exemplarisch mit einem Personen- und Ortsregister,[10] die vollautomatisch aus der Kontextdatenbank erzeugt wurden. Im linken Feld befindet sich wiederum die Urkundentranskription, im rechten Feld der alphabetisch sortierte Personenindex, anschließend der Ortsindex. Bei beiden Indizes wurde die Funktion der Personen und Orte im Rahmen des Urkundsgeschäfts mit aufgeschlüsselt.
|
Personen |
Orte |
|
• Aussteller |
• Ausstellungsort |
|
• Empfänger |
• Aussteller |
|
• Bürge |
• Empfänger |
|
• Zeuge |
• Bürge |
|
• Siegler |
• Zeuge |
|
• weitere Person (ohne Rechtsfunktion) |
• Siegler |
|
• Schreiber |
• erwähnter Ort |
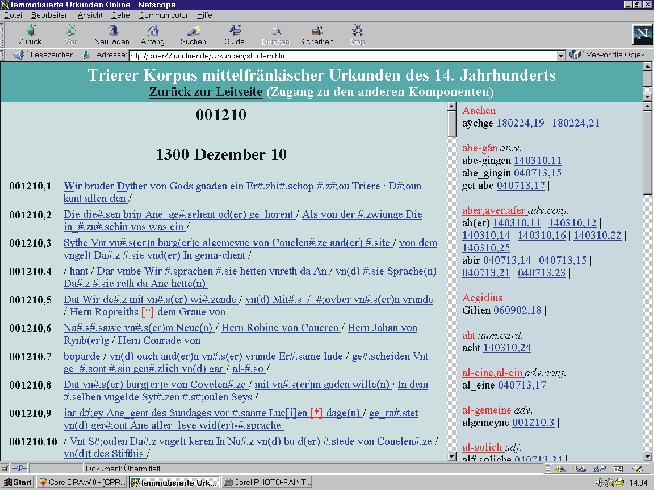
Abbildung 7: Elektronische Publikation des Trierer Korpus – »Text und lemmatisierter Index«
Die sprachwissenschaftliche Aufbereitung und Auswertung geschieht über den lemmatisierten Index. Es wurde mittels eines im Projekt entwickelten Verfahrens eine halbautomatische Voll-Lemmatisierung vorgenommen. Im linken Feld mit der Urkundentranskription ist nun jede Wortform als Link realisiert, das den Zugriff auf das rechte Feld mit dem lemmatisierten Index ermöglicht. Der Lemma-Ansatz richtet sich nach dem Mittelhochdeutschen Handwörterbuch von Matthias Lexer.[11] Die Lemmata sind rot abgebildet, die alphabetisch darunter angeordneten belegten Wortformen schwarz. Nicht bei Lexer gebuchte Lemmata erhalten einen Asterisken. Die Urkundenzeilen-Referenzen hinter der Wortform führen zur jeweiligen Textstelle im linken Feld.
Die roten Lemmata sind mit Ausnahme der Asterisk-Lemmata sowie der Eigennamen ebenfalls als Link realisiert, die über eine Verknüpfung mit dem elektronischen Lexer in den elektronischen Verbund mittelhochdeutscher Wörterbücher[12] führen. Die hier erstmals erprobte Verknüpfung eines lemmatisierten Textkorpus mit dem elektronischen Wörterbuchverbund wird neben der einfachen Nachschlagefunktion auch umfangreiche Rechercheanwendungen ermöglichen. Vorstellbar wäre zum Beispiel eine Wortschatzuntersuchung des »Trierer Korpus« nach textsortenspezifischen oder regionalen Kriterien.
Über den lemmatisierten Index können in der endgültigen Publikation also nicht nur die Urkundentexte systematisch nach bestimmten Lemmata recherchiert werden, sondern auch weitere Informationen aus den mittelhochdeutschen Wörterbüchern per Mausklick abgerufen und individuell zusammengestellt werden.
Für die endgültige elektronische Version des Trierer Korpus ist geplant, daß der/die Benutzer/in über die Recherchemaske gezielt ein ›eigenes‹ Korpus zusammenstellen kann. Es besteht dann ferner die Wahlmöglichkeit, als Erschließungsinstrument alle Kategorien im Kontext einer Urkunde darstellen zu lassen, oder bestimmte beziehungsweise eine Kategorie auszuwählen, wie es bislang nur mit dem Personen- und Ortsindex realisiert ist.
Sämtliche EDV-gestützten Arbeitsschritte wurden seit Projektbeginn mit dem Tübinger Programmpaket TUSTEP[13] realisiert. Dazu gehören die Textaufnahme, die Verwaltung der Kontextdatenbank, verschiedenste Index- und Auswertungsschritte,[14] die großenteils automatische Auszeichnung der strukturierten Grunddaten durch TEI-konformes inhaltlich-strukturelles Markup,[15] die Satzherstellung, die Herstellung der HTML-Version, die Internet-Recherche über die CGI-Schnittstelle sowie die Vernetzung mit dem elektronischen Lexer, was bedeutet, daß alle Arbeitsschritte ohne Konvertierungen erfolgt sind. Gerade längerfristige Vorhaben profitieren von der Beständigkeit der Programmentwicklung sowie der garantierten Kompatibilität der TUSTEP-Versionen – nicht zuletzt auch in bezug auf verschiedene Betriebssysteme.
Datengrundlage sowohl für eine Buchpublikation des Trierer Korpus einschließlich diverser Register als auch für die elektronische Publikation sind drei Dateien:
Die erste Datei enthält die Texte, das heißt die Urkundentranskriptionen. Ein Datensatz[16] entspricht darin einer Urkundenzeile; jede Zeile ist durch eine eindeutige Referenz identifizierbar. Die Abbildung zeigt den Ausschnitt aus einer TUSTEP-Datei mit Markup.
0.1 |<html>
0.2 |<head>
0.3 |<title> Trierer Korpus online – Texte </title>
0.3/1 |<base target="regest">
0.4 |</head>
0.5 |<body bgcolor="C7E2E2">
1.1 |<div type="urkunde" id="u001210">
1.2 |<kopf> 001210 <date> 1300 Dezember 10 </date> </kopf>
1.3 |<div type="uzeile" id="u001210,1"> <hi rend="bold">W</hi>ir bruder <ref
|type="treg" n="r001210,05"><hi rend="bold"> D</hi>yther von Gods gnaden ein
|Er#.zbi#.schop #.z#;ou Triere</ref> · D#;oun kunt allen den / </div>
1.4 |<div type="uzeile" id="u001210,2"> die die#.sen brip Ane_ge#.sehent od(er)
|ge_horent / Als von der #.zwiunge die in_#.zu#.schin vns was ein / </div>
1.5 |<div type="uzeile" id="u001210,3"> Sythe vnt vn#.s(er)n burg(er)e algemeyne von
|<ref type="treg" n="r001210,06"> Couelen#.ze</ref> and(er) #.site / von dem
|vngelt da#.z #.sie vnd(er) in gema- / </div>
1.6 |<div type="uzeile" id="u001210,4"> chent hant / Dar vmbe wir #.sprachen #.sie
|hetten vnreth da An / vn(d) #.sie Sprache(n) da#.z #.sie reth da Ane hette(n)
|</div>
1.7 |<div type="uzeile" id="u001210,5"> Dat wir de#.z mit vn#.s(er) wi#.zende /
|vn(d) Mit#.s_/_#;ovber vn#.s(er)n vrunde / hern <ref type="treg"
|n="r001210,7001"> Ropreiths </ref> <note type="oder" n="u001210,5"> Ropreiths
|<hi rend="italics">oder</hi> Ropreichs? <hi rend="italics">Unterscheidung
|von</hi> t <hi rend="italics">und</hi> c <hi rend="italics">generell
|schwierig.</hi></note> <ref type="treg" n="r001210,0701"> dem Graue von</ref>
|</div>
Die zweite Datei enthält die Kontextinformationen zu den Urkunden. Diese Datei ist datenbankartig strukturiert, so daß jede einzelne Information nicht nur mit der Referenz der entsprechenden Urkunden(zeile) korrespondiert, sondern auch selbst mit einer eindeutigen Kennung versehen ist. Solche Kennungen und Korrespondenzen können zum Teil automatisch generiert werden. Diese Datenstruktur, anhand derer von jeder einzelnen Information auf die betreffende Textstelle und umgekehrt zugegriffen werden kann, ist die Voraussetzung für die zum großen Teil maschinell, also mittels TUSTEP-Programmen, erzeugte Datenbasis der elektronischen Publikation. Sie ist ebenfalls für die Realisierung der Suchroutinen erforderlich.
0.1 |<html>
0.2 |<head>
0.3 |<title> Trierer Korpus Online – Kontext </title>
0.4 |<base target="urktext">
0.5 |</head>
0.6 |<body>
1.1 |<div type="regest" id="r001210">
1.2 |<div type="reint" id="r001210,00"> </div>
1.3 |<div type="reint" id="r001210,01"> x001210 </div>
1.4 |<div type="reint" id="r001210,02"> Koblenz, LHA, Best. 623 Nr. 28 </div>
1.5 |<div type="reint" id="r001210,03"> </div>
1.6 |<div type="reint" id="r001210,04"> 1300 XII 10 </div>
1.7 |<div type="reint" id="r001210,05"> Dieter von Nassau, Erzbischof von Trier
|(1300-1307), Bruder des Königs Adolf von Nassau. Dieter, ein ehemaliger
|Dominikaner, wurde von Papst Bonifazius VIII. gegen den vom Domkapitel
|erwählten Archidiakon und Kölner Domprobst Heinrich von Virneburg, den späteren
|Kölner Erzbischof, auf den erzbischöflichen Stuhl erhoben. Dieter widmete sich
|zunächst dem päpstlichen Interesse der Bekämpfung König Albrechts. Erst ab 1302
|wendete er sich primär seinen territorialpolitischen Aufgaben zu. Seine
|Herrschaft war teilweise von Schwächen gekennzeichnet, grundsätzliche Verluste
|oder substantielle Rückschritte hatte er jedoch nicht zu verantworten. <ref
|type="uzeile" n="u001210,1">001210,1</ref> <ref type="uzeile"
|n="u001210,18">001210,18</ref> </div>
1.8 |<div type="reint" id="r001210,06"> Stadt Koblenz <ref type="uzeile"
|n="u001210,3">001210,3</ref> <ref type="uzeile" n="u001210,8">001210,8</ref>
|<ref type="uzeile" n="u001210,10">001210,10</ref> <ref type="uzeile"
|n="u001210,14">001210,14</ref> </div>
1.9 |<div type="reint" id="r001210,07"> </div>
1.10 |<div type="reint" id="r001210,7001"> Ruprecht, Graf von Nassau <ref
|type="uzeile" n="u001210,5">001210,5</ref> </div>
Die dritte Datei enthält den Thesaurus für die Lemmatisierung. Ein besonderer Vorteil lag in der Verwendung der Lexer-Ausgangsdateien des Projekts Mittelhochdeutsche Wörterbücher auf CD-ROM und im Internet im TUSTEP-Format als Thesaurusdatei für das halbautomatische Lemmatisierungsverfahren,[17] da sie die Seiten-Zeilen-Referenzen des gedruckten Lexer enthalten. Endergebnis des Lemmatisierungsvorgangs ist eine Datei, die den vollemmatisiertenen Text mit Lexer-Seiten-Zeilen-Referenzen zum jeweiligen Lemma enthält.
100011.30 |#F+aber, aver, afer#F- #/+adv. u. conj.#/-
100011.30/001 |==aber
100011.30/002 |==abir
100011.30/003 |==ab(er)
[...]
100029.43 |#F+aht#F- #/+num. card.#/-
100029.43/001 |==aht
100029.43/002 |==acht
100029.43/003 |==eht
100029.43/004 |==echte
100029.46 |#F+aht-bære, ahte-bære#F- #/+adj.#/-
[...]
100036.16 |#F+al-eine, al-ein#F- #/+adv. u. conj.#/-
100036.16/001 |==al_eine
100036.16/002 |==alein
[...]
100037.1 |#F+al-gemeine#F- #/+adv.#/-
100037.1/001 |==al_gemeine
100037.1/002 |==algemeine
100037.1/003 |==algemeyne
[...]
100042.43 |#F+al-solich, -solch#F- #/+pron. adj.#/-
100042.43/001 |==al#.soliche
100042.43/002 |==al_#.s#;oulich
100042.43/003 |==al_#.s#;oulich
100042.43/004 |==al_#.s#;oulig
100042.43/005 |==al#.s#;oulig
Auschnitt aus dem Lexer-basierten Thesaurus mit Lexer-Seiten-Zeilen-Referenzen
1.1 |<p>
1.2 |<kopf> 001210 <date> 1300 Dezember 10 </date> </kopf>
1.3 |u001210,1\\ <b>W</b>ir::[wir{{pron.300925.12] bruder::[bruoder{{stm.an.100369.26]
|<b>D</b>yther::[Diether] von::[von,vone{{präp.adv.300456.48] Gods::[Gott]
|gnaden::[ge-nâde{{stf.100850.12] ein::[ein{{zahlw.pron.100520.52]
|Er#.zbi#.schop::[erze-bischof{{stm.100704.13] #.z#;ou::[ze,zuo{{präp.301036.13]
|Triere::[Trier] D#;oun::[tuon{{an.v.201575.43] kunt::[kunt{{adj.101782.14]
|allen::[al{{adj.100033.3] den::[dër,diu,da#.z{{pron.100419.16] /
1.4 |u001210,2\\ Die::[dër,diu,da#.z{{pron.100419.16] die#.sen::[diser{{pron.100440.22]
|brip::[brief{{stm.100352.21] Ane_ge#.sehent::[ane-sëhen{{stv.100062.20]
|od(er)::[ode,od,oder{{conj.200140.22] ge_horent::[h#.ören{{swv.101339.44] /
|Als::[alsô,alse,als{{adv.^2\100042.26] von::[von,vone{{präp.adv.300456.48]
|der::[dër,diu,da#.z{{pron.100419.16] #.zwiunge::[zweiunge{{stf.301208.22]
|Die::[dër,diu,da#.z{{pron.100419.16] in_#.zu#.schin::[zwisc,zwisch{{adj.301220.2]
|vns::[wir{{pron.300925.12] was::[wësen{{stv.300799.1]
|ein::[ein{{zahlw.pron.100520.52] /
1.5 |u001210,3\\ Sythe::[sîte,sît{{swstf.200942.11] Vnt::[unde{{conj.201775.42]
|vn#.s(er)n::[wir{{pron.300925.12] burg(er)e::[burgære{{stm.100395.32]
|algemeyne::[al-gemeine{{adv.100037.1] von::[von,vone{{präp.adv.300456.48]
|Couelen#.ze::[Koblenz] and(er)::[ander{{adj.100055.49]
|#.site::[sîte,sît{{swstf.200942.11] / von::[von,vone{{präp.adv.300456.48]
|dem::[dër,diu,da#.z{{pron.100419.16] vngelt::[un-gëlt{{stnm.201845.21]
|Da#.z::[dër,diu,da#.z{{pron.100419.16] #.sie::[sie{{pron.200907.52]
|vnd(er)::[under{{präp.adv.201777.30] In::[ër,sie,ë#.z{{pron.100604.45]
|gema-chent::[machen{{swv.^1\102001.40] /
Ausschnitt aus der lemmatisierten Datei
Bei der konkreten Verknüpfung wurde folgende Vorgehensweise gewählt: Als feste, jedem zugängliche Referenz bieten sich die Seiten-Zeilen-Referenzen des gedruckten Lexer an. Diese werden daher in die lemmatisierte Textdatei integriert, auch wenn sie tatsächlich nicht in der HTML-Ankerstruktur des elektronischen Lexer abgebildet sind. Eine Umrechnung auf die lexerinternen Identifier erfolgt in dem Programm, das die HTML-Dateien aus den oben gezeigten TUSTEP-Basis-Dateien erstellt. Dazu stellt das Lexer-Projekt eine computergenerierte Liste der Entsprechungen von Seiten-Zeilen-Referenzen und Lexer-internen Referenzen zur Verfügung, mit deren Hilfe die ›richtigen‹ Links erzeugt werden können.[18] Der Vorteil dieses Verfahrens liegt darin, daß jeder Bearbeiter, der einen lemmatisierten Text mit dem Lexer verknüpfen möchte, mit den Seiten-Zeilen-Referenzen des gedruckten Lexers arbeiten kann, ohne die Datei- und Anker-Struktur des Lexer-Projekts kennen zu müssen. Seine Dateien benötigen zunächst nur den HTML-üblichen Link zur Seiten-Zeilen-Referenz des Lexer, die dann mit Unterstützung der Bearbeiter des elektronischen Lexer jederzeit problemlos umgerechnet werden. Vom Lexer aus schließlich wird der Benutzer zu den anderen Wörterbüchern des elektronischen Wörterbuchverbunds gelangen.
Dieses hier beschriebene modellhafte Vernetzungsverfahren erprobt demnach ein dezentrales Arbeiten bei der Verfügbarmachung historischer Quellen und Hilfsmittel in digitaler Form.
Andrea Rapp (Trier)
Dr. Andrea Rapp
FB II / Germanistik
Universität Trier
54286 Trier
0651/201-3363
rappand@uni-trier.de
http://www.uni-trier.de/uni/fb2/germanistik/aedph_mitarbeiter.html
[1] Das
Teilprojekt wird geleitet von Prof. Dr. Kurt Gärtner (Germanistik) und
Prof. Dr. Günter Holtus (Romanistik). Vergleiche die Informationen auf der
Homepage des SFB beziehungsweise der Projekte unter
<http://www.uni-trier.de/infos/sfb235/sfb235.htm>
(8.9.1999) sowie die Sammelbände des Teilprojekts: Kurt
Gärtner/Günter Holtus (Hg.): Beiträge zum Sprachkontakt und zu
den Urkunden- und Literatursprachen zwischen Maas und Rhein (Trierer Historische
Forschungen 29). Trier: - Trierer Historische Forschungen 29 = Verlag Trierer
Historische Forschungen 1995; Kurt Gärtner/Günter Holtus (Hg.):
Urkundensprachen im germanisch-romanischen Grenzgebiet. Beiträge zum
Kolloquium am 5./6. Oktober 1995 in Trier (Trierer Historische Forschungen 35).
Mainz: Zabern 1997; Kurt Gärtner/Günter Holtus/Andrea Rapp/Harald
Völker (Hg.): Skripta, Schreiblandschaften und Standardisierungstendenzen.
Urkundensprachen im Grenzbereich von Germania und Romania im 13. und 14.
Jahrhundert (Trierer Historische Forschungen). Mainz: Zabern [im
Druck].
[2] Im
Rahmen der Erforschung der regionalen älteren Schreibsprachen liegt die
Kenntnis des moselfränkischen Raumes besonders im Argen. Als Indikator
dafür können die einschlägigen Grammatiken der älteren
Sprachstufen dienen: In der Paulschen Grammatik (Hermann Paul: Mhd. Grammatik.
24. Auflage von Peter Wiehl und Siegfried Grosse (Sammlung kurzer Grammatiken
germanischer Dialekte A,2). Tübingen: Niemeyer 1998) wurden zum Teil Belege
aus John Meiers veralteter Untersuchung zu Bruder Hermanns moselfränkischer
Yolanda-Vita eingearbeitet (J.M.: Bruder Hermann. Leben der Gräfin Iolande
von Vianden (Germanistische Abhandlungen 7). Breslau: Köbner 1889;
Nachdruck Hildesheim, New York: Olms 1977.). Auf deren Ausgabe in weitgehend
normalisierter Textgestalt, die zudem auf einer Abschrift des 17. Jahrhunderts
beruht, wird ferner in den Bänden zur Lautlehre der Grammatik des
Frühneuhochdeutschen zurückgegriffen (Hugo Moser/Hugo Stopp/Werner
Besch (Hg.): Grammatik des Frühneuhochdeutschen (Germanische Bibliothek.
Reihe 1: Sprachwissenschaftliche Lehr- und Elementarbücher). Bd. 1,1ff.,
Heidelberg: Winter 1970ff.). Zugespitzt formuliert, ist die normalisierte
Ausgabe der Yolanda-Vita aus dem letzten Jahrhundert in einigen Bereichen der
Sprachgeschichtsschreibung die wichtigste beziehungsweise einzige Quelle
für den Zeitraum zwischen 1050-1700!
[3] Corpus
der altdeutschen Originalurkunden bis zum Jahr 1300, Bd. I: 1200-1282, hg. von
Friedrich Wilhelm. Lahr: Schauenburg 1932, Bd. II: 1283-1292, hg. von Friedrich
Wilhelm und Richard Newald. Lahr: Schauenburg 1943, Bd. III: 1293-1296, hg. von
Richard Newald, Helmut de Boor und Diether Haacke. Lahr: Schauenburg 1962, Bd.
IV: 1297-(Ende 13. Jahrhundert), hg. von Helmut de Boor und Diether Haacke.
Lahr: Schauenburg 1963, Bd. V: Nachträge, hg. von Helmut de Boor, Diether
Haacke und Bettina Kirschstein. Lahr: Schauenburg 1986. Regesten, hg. von Helmut
de Boor, Diether Haacke und Bettina Kirschstein. Lahr: Schauenburg 1963ff. WMU =
Wörterbuch zur mittelhochdeutschen Urkundensprache auf der Grundlage des
Corpus der altdeutschen Originalurkunden bis zum Jahr 1300. Unter der Leitung
von Bettina Kirschstein und Ursula Schulze erarbeitet von Sibylle Ohly und Peter
Schmitt (Veröffentlichungen der Kommission für Deutsche Literatur des
Mittelalters der Bayerischen Akademie der Wissenschaften). Bd. 1ff., Berlin:
Schmidt 1994ff. Schreibortverzeichnis zum Wörterbuch der
Mittelhochdeutschen Urkundensprache. Unter der Leitung von Bettina Kirschstein
und Ursula Schulze erarbeitet von Sibylle Ohly und Peter Schmitt
(Veröffentlichungen der Kommission für Deutsche Literatur des
Mittelalters der Bayerischen Akademie der Wissenschaften). Berlin: Schmidt
1991.
[4] Siehe
dazu die Projektbilanz zu den Quellen des 13. Jahrhunderts bei Kurt
Gärtner/Günter Holtus/Andrea Rapp/Harald Völker: Urkunden des 13.
Jahrhunderts als Quellen sprachlicher Untersuchungen zum Westmitteldeutschen und
Ostfranzösischen. Korpus und Auswertungsbeispiele. In: Urkundensprachen im
germanisch-romanischen Grenzgebiet. Beiträge zum Kolloquium am 5./6.
Oktober in Trier, hg. von Kurt Gärtner/Günter Holtus (Trierer
Historische Forschungen 35). Mainz: Zabern 1997, S. 21-138.
[5] Es
handelt sich um folgende Ausfertigungen: Koblenz, Landeshauptarchiv, Best. 623,
Nr. 28 sowie Best. 33, Nr. 15032; München, Bayerisches Hauptstaatsarchiv,
Sponheim U.109, U. 165 sowie U. 206; Köln, Hauptstaatsarchiv, Domstift
K/760; siehe
<http://gaer27.uni-trier.de/Urkunden/welcome.htm>
(8.9.1999).
[6] Jede
einzelne Ausfertigung ist zunächst in einer eigenen Datei abgelegt. Kennung
oder Referenz entsprechen dem Dateinamen.
[7] Parallelurkunden
erhalten zur Kennzeichnung einen Kleinbuchstaben (x071027a, x071027b); Urkunden,
die zufällig am selben Tag ausgestellt wurden, eine Ziffernextension
(x280924.1, x280924.2).
[8] Diese
Schlagwörter werden über einen Index als Suchbegriffe abrufbar
beziehungsweise anwählbar sein. Ähnliches ist auch für andere
Kategorien denkbar.
[9] In
der ›Vorabpublikation‹ sind also noch keine ›beliebigen‹
Ordnungsmuster der Texte selbst herstellbar.
[10] Ein
solch spezifizierter Index ist für jede Kategorie der Kontextdatenbank
leicht vollautomatisch realisierbar und wird in der endgültigen Publikation
auch für jede Kategorie zur Verfügung stehen.
[11] Mittelhochdeutsches
Handwörterbuch von Matthias Lexer, 3 Bde. Nachdruck der Ausgabe Leipzig
1872-1878. Mit einer Einleitung von Kurt Gärtner, Stuttgart: Hirzel
1992.
[12] <http://gaer27.uni-trier.de/MWV-online/MWV-online.html>
(8.9.1999). Der elektronische Wörterbuchverbund wird unter der Leitung von
Kurt Gärtner erarbeitet von Thomas Burch und Johannes Fournier. Ihnen sei
an dieser Stelle für die Zusammenarbeit und die Unterstützung bei der
Vernetzung ganz herzlich gedankt.
[13] Tuebinger
System von Textverarbeitungsprogrammen © ZDV
Universität Tübingen; siehe die TUSTEP-Homepage
<http://www.uni-tuebingen.de/zdv/tustep/index.html>
(8.9.1999) sowie die Homepage der International Tustep User Group
<http://www.germanistik.uni-wuerzburg.de/itug.html>
(8.9.1999).
[14] Dazu
gehören zum Beispiel einfache Wortformenregister, Kwic-Indizes,
Vergleicheprozeduren für Parallelurkunden oder ein halbautomatisches
Lemmatisierungsverfahren.
[15] Vergleiche
Lou Burnard/Michael Sperberg-McQueen: Guidelines for Electronic Text Encoding
and Interchange (TEI P3) (electronic book library volume 2). Providence RI 1994;
ferner
<http://etext.virginia.edu/TEI.html>
(8.9.1999) sowie auch die ständig aktualisierte SGML-Bibliographie unter
<http://www.oasis-open.org/cover/biblio.html>
(8.9.1999).
[16] Zur
Struktur von TUSTEP-Dateien und Datensätzen vergleiche Lernbuch TUSTEP.
Einführung in das Tübinger System von Textverarbeitungsprogrammen,
bearbeitet von Winfried Bader. Tübingen: Niemeyer 1995, S. 25f.; zu den
Anwendungsmöglichkeiten strukturierter Dateien in und mit TUSTEP vergleiche
ebenda, S. 250ff.
[17] Überarbeitete
Version des bei Stephan Habscheid: Die Kölner Urkundensprache des 13.
Jahrhunderts. Flexionsmorphologische Untersuchungen zu den deutschen Urkunden
Gottfried Hagens (1262-1274) (Rheinisches Archiv 135). Köln: Böhlau
1997, S. 20-30, sowie Andrea Rapp: Zur computergestützten Untersuchung
westmitteldeutscher Urkunden des 13. Jahrhunderts. In: Gärtner/Holtus:
Urkundensprachen im germanisch-romanischen Grenzgebiet, 1997 (wie Fußnote
1), S. 181-198, beschriebenen Verfahrens.
[18] Als alternative Vorgehensweise ist auch eine Verknüpfung über die Lemmata selbst denkbar, doch bleibt dann das Problem der Homographentrennung. Dies wird durch die Angabe der Seiten-Zeilen-Referenz umgangen.